环境安装
安装CentOS
CentOS安装docker
docker安装redis
docker安装mysql
docker安装rabbitmq
.gitignore文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 target/ pom.xml.tag pom.xml.releaseBackup pom.xml.versionsBackup pom.xml.next release.properties dependency-reduced-pom.xml buildNumber.properties .mvn/timing.properties # https://github.com/takari/maven-wrapper#usage-without-binary-jar .mvn/wrapper/maven-wrapper.jar **/mvnw **/mvnw.cmd **/.mvn **/target **/.gitignore .idea
项目结构
商品服务product
存储服务ware
订单服务order
优惠券服务coupon
用户服务member
每个模块导入web和openFeign
父模块创建pox.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.boyiz.gulimall</groupId> <artifactId>gulimall</artifactId> <version>0.0.1-SNAPSHOT</version> <name>gulimall</name> <description>gulimall聚合服务</description> <packaging>pom</packaging> <modules> <module>gulimall-coupon</module> <module>gulimall-member</module> <module>gulimall-order</module> <module>gulimall-product</module> <module>gulimall-ware</module> <module>renren-fast</module> <module>renren-generator</module> <module>gulimall-common</module> 后续模块自行添加... </modules> </project>
逆向生成mapper,dao,entity,controller,service git clone https://gitee.com/renrenio/renren-generator.git
配置application.yml中mysql信息
配置generator.properties
1 2 3 4 5 6 7 8 9 10 11 12 13 #代码生成器,配置信息 #主目录 mainPath=com.boyiz #包名 package=com.boyiz.gulimall moduleName=ware #模块名 author=boyiz #Email email=xianpeoplenocome@gmail.com #表前缀(类名不会包含表前缀) tablePrefix=wms_
运行RenrenApplication,访问http://localhost:80,生成代码
创建commom模块 每个微服务的公共依赖、工具类等都在此配置,其他模块引入common。
mybatis-plus
lombok
mysql
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 ##重要 <!-- nacos 服务注册--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> <exclusions> <exclusion> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-ribbon</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-loadbalancer</artifactId> <version>3.0.3</version> </dependency> <dependencyManagement> <dependencies> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2.2.8.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement>
整合Mybatis-plus 整合mybatis-plus,各模块类同
1 2 3 4 5 6 7 @MapperScan("com/boyiz/gulimall/product/dao") @SpringBootApplication public class GulimallProductApplication { public static void main(String[] args) { SpringApplication.run(GulimallProductApplication.class, args); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 #application.yml spring: datasource: username: root password: root url: jdbc:mysql://8.8.8.8:3306/gulimall_pms?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai #配置数据库地址和各模块对应的数据库名 driver-class-name: com.mysql.cj.jdbc.Driver mybatis-plus: mapper-locations: classpath:/mapper/**/*.xml #配置各个mapper.xml文件路径 global-config: db-config: id-type: auto #id自增
SpringCloud Alibaba 搭配环境 1 2 3 4 5 6 7 8 9 10 11 12 13 在common的pom.xml中加入 # 下面是依赖管理,相当于以后再dependencies里引spring cloud alibaba就不用写版本号, 全用dependencyManagement进行管理 <dependencyManagement> <dependencies> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2.1.0.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement>
Nacos
一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。 作为我们的注册中心和配置中心。
使用文档
修改 common中的pom.xml 文件,引入 Nacos Discovery Starter。
1 2 3 4 <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency>
在各模块的application.yml 配置文件中配置 Nacos Server 地址和微服务名称
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 spring: application: name: gulimall-coupon #微服务名称 datasource: username: root password: root url: jdbc:mysql://8.1.9.1:3306/gulimall_sms?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai driver-class-name: com.mysql.cj.jdbc.Driver cloud: nacos: discovery: server-addr: 39.107.96.120:8848 # Nacos Server 地址 mybatis-plus: mapper-locations: classpath:/mapper/**/*.xml global-config: db-config: id-type: auto server: #服务端口号 port: 12000
下载安装Nacos Server https://github.com/alibaba/nacos 解压运行.cmd或.sh (以standalone模式运行,需修改)
docker启动nacos
1 docker run --name nacos-waper -e MODE=standalone -p 8848:8848 -p 9848:9848 -p 9849:9849 -d nacos/nacos-server
配置服务注册与发现 @EnableDiscoveryClient @EnableDiscoveryClient 注解开启服务注册与发现功能
各模块类同
1 2 3 4 5 6 7 8 @MapperScan("com/boyiz/gulimall/product/dao") @SpringBootApplication @EnableDiscoveryClient //开启服务注册与发现功能 public class GulimallProductApplication { public static void main(String[] args) { SpringApplication.run(GulimallProductApplication.class, args); } }
application.yml
1 2 3 4 5 spring: cloud: nacos: discovery: server-addr: 39.107.96.120:8848
访问 ip:8848/nacos,默认账号密码nacos
‼️远程调用测试 在Spring cloud应用中,当我们要使用feign客户端时,一般要做以下三件事情 :
⚠️1.使用注解@EnableFeignClients启用feign客户端;
⚠️2.使用注解@FeignClient 定义feign客户端 ;
⚠️3.使用注解@Autowired使用上面所定义feign的客户端 ;
远程调用别的服务
1 2 3 4 5 6 7 8 9 10 Feign与注册中心 spring cloud feign 声明式远程调用 feign是一个声明式的HTTP客户端,他的目的就是让远程调用更加简单。给远程服务发的是HTTP请求。 会员服务想要远程调用优惠券服务,只需要给会员服务里引入openfeign依赖,远程调用其他服务的能力。 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency>
编写接口,@FeignClient注解,value值的要调用的微服务名称
member下建包feign,新建接口CouponFeignService
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 /** * 这是一个声明式远程调用 * @FeignClient * gulimall-coupon 表示要调用的微服务名称,同各模块yml中的application name */ ⚠️2 @FeignClient("gulimall-coupon") //在此表示member远程调用coupon服务 public interface CouponFeignService { @RequestMapping("/coupon/coupon/member/list") //要补全membercoupon()方法路径 public R membercoupon(); //CouponController中membercoupon()方法 } ##MemberController.java @RestController @RequestMapping("member/member") public class MemberController { ⚠️3 @Autowired CouponFeignService couponFeignService; @RequestMapping("/coupons") public R test() { MemberEntity memberEntity = new MemberEntity(); memberEntity.setNickname("ZS"); R membercoupons = couponFeignService.membercoupon(); return R.ok().put("member", memberEntity).put("coupons", membercoupons.get("coupon")); } } ##CouponController.java @RestController @RequestMapping("coupon/coupon") public class CouponController { @Autowired private CouponService couponService; @RequestMapping("/member/list") public R membercoupon() { CouponEntity couponEntity = new CouponEntity(); couponEntity.setCouponName("100 - 10"); return R.ok().put("coupon", Arrays.asList(couponEntity)); } } @SpringBootApplication ⚠️1 ###注解@EnableFeignClients告诉框架扫描所有使用注解@FeignClient定义的feign客户端 @EnableFeignClients(basePackages = "com.boyiz.gulimall.member.feign") @EnableDiscoveryClient public class GulimallMemberApplication { public static void main(String[] args) { SpringApplication.run(GulimallMemberApplication.class, args); } }
启动服务,进入http://localhost:8000/member/member/coupons
Nacos作为配置中心 首先,修改 pom.xml 文件,引入 Nacos Config Starter。
1 2 3 4 <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency>
在模块创建 bootstrap.properties 配置文件中配置 Nacos Config 元数据
1 2 3 spring.application.name=gulimall-coupon ##应用名 spring.cloud.nacos.config.server-addr=127.0.0.1:8848 ##配置中心地址
启动 Nacos Server 并在配置管理中添加配置
DataId默认规则:应用名.properties
给应用名.properties 中添加配置
服务动态获取配置
1 2 3 4 5 6 7 8 9 10 11 12 13 @RefreshScope:动态获取并刷新配置 @Value("${配置项名}"):获取到配置 @RefreshScope @RestController @RequestMapping("coupon/coupon") public class CouponController { @Value("${coupon.user.name}") private String name; @Value("${coupon.user.age}") private Integer age; }
配置中心和配置文件中共有的项优先使用配置中心的内容
细节
加载多配置集 将application.yml拆分为三个配置集
在bootstrap.properties 配置文件中设置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 spring.application.name=gulimall-coupon spring.cloud.nacos.config.server-addr=ip:8848 spring.cloud.nacos.config.namespace=14c37bfc-16e4-4a98-a1fa-3692dabe484d spring.cloud.nacos.config.group=coupon spring.cloud.nacos.config.extension-configs[0].data-id=datasource.yml spring.cloud.nacos.config.extension-configs[0].group=dev spring.cloud.nacos.config.extension-configs[0].refresh=true spring.cloud.nacos.config.extension-configs[1].data-id=mybatis.yml spring.cloud.nacos.config.extension-configs[1].group=dev spring.cloud.nacos.config.extension-configs[1].refresh=true spring.cloud.nacos.config.extension-configs[2].data-id=other.yml spring.cloud.nacos.config.extension-configs[2].group=dev spring.cloud.nacos.config.extension-configs[2].refresh=true
服务配置 GulimallGatewayApplication
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 网关服务,端口88,所有api都访问此端口,配合nacos完成路由选择与路径重写 spring: cloud: gateway: routes: #配置各个服务的路由与路径重写 - id: product_route uri: lb://gulimall-product predicates: - Path=/api/product/** filters: - RewritePath=/api/(?<segment>.*), /$\{segment} #把api删掉 - id: thirdparty_route uri: lb://gulimall-thirdparty predicates: - Path=/api/thirdparty/** filters: - RewritePath=/api/thirdparty/(?<segment>.*), /$\{segment} #把api删掉 - id: admin_route uri: lb://renren-fast #lb: 负载均衡,通过项目名进行请求 predicates: - Path=/api/** #前端项目都用 /api /设置低优先级(往后放),否则在前会先过滤所有请求 # 目前配置 http://localhost:88/api/captcha.jpg # 实际路由后 http://renren-fast:8080/api/captcha.jpg # 真正路径 http://localhost:8080/renren-fast/api/captcha.jpg filters: - RewritePath=/api/(?<segment>.*), /renren-fast/$\{segment} #以下为 跨域配置 globalcors: cors-configurations: '[/**]': allow-credentials: true allowedOriginPatterns: '*' allowedMethods: '*' allowedHeaders: '*'
GulimallProductApplication
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 产品服务,端口10000 spring: application: name: gulimall-product datasource: username: root password: url: jdbc:mysql://8.8.8.8:3306/gulimall_pms?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai driver-class-name: com.mysql.cj.jdbc.Driver cloud: nacos: discovery: server-addr: 8.8.8.8:8848 main: lazy-initialization: true #springboot2.6开始,默认禁止循环依赖 jackson: date-format: yyyy-MM-dd HH:mm:ss //配置时间格式 mybatis-plus: mapper-locations: classpath:/mapper/**/*.xml global-config: db-config: id-type: auto logic-delete-value: 1 logic-not-delete-value: 0 server: port: 10000 logging: level: com.boyiz.gulimall: debug #设置com.boyiz.gulimall包下所有都是debug级别 alibaba: #aliyun OSS设置 cloud: access-key: secret-key: oss: endpoint:
SpringCloud OpenFeign 导入依赖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency> #增加 spring cloutd的依赖: <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>${spring-cloud.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement>
Feign Client @EnableFeignClients
1 2 3 4 5 6 7 8 9 10 11 ## 在主类上增加注解 @EnableFeignClients @MapperScan("com/boyiz/gulimall/product/dao") @SpringBootApplication @EnableDiscoveryClient ⚠️//开启远程调用功能,basePackages指定了要扫描声明了Feign客户端的接口。 @EnableFeignClients(basePackages = "com.boyiz.gulimall.product.feign") public class GulimallProductApplication { public static void main(String[] args) { SpringApplication.run(GulimallProductApplication.class, args); } }
@FeignClient
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 ## 在product包下新建feign包,创建CouponFeignService.java @FeignClient("gulimall-coupon") //调用gulimall-coupon模块的服务 public interface CouponFeignService { /** * 此方法调用gulimall-coupon远程服务 * 调用服务中的 @PostMapping("coupon/spubounds/save") 这个请求 * @param spuBoundTo * @return */ @PostMapping("coupon/spubounds/save") //此处要填写 对应服务controller 完整路径 R saveSpuBounds(@RequestBody SpuBoundTo spuBoundTo); @PostMapping("coupon/skufullreduction/saveinfo") R saveSkuReduction(@RequestBody SkuReductionTo skuReductionTo); /** * 流程: * 在SpuInfoServiceImpl 实现中,调用 couponFeignService.saveSpuBounds(spuBoundTo); * 1、@RequestBody将spuBoundTo 转为Json * 2、找到gulimall-coupon远程服务,给 coupon/spubounds/save 发送请求 * 同时将Json放在请求体中 * 3、对方服务接收到请求,@RequestBody 将Json转换为实体 * ⚠️只要Json数据模型互相兼容,双方服务无需使用同一个TO */ } @Service("spuInfoService") public class SpuInfoServiceImpl extends ServiceImpl<SpuInfoDao, SpuInfoEntity> implements SpuInfoService { @Autowired CouponFeignService couponFeignService; //实现类中自动注入,调用其方法。 }
JSR303
引入依赖
1 2 3 4 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-validation</artifactId> </dependency>
在实体类中使用
1 2 3 4 5 6 7 8 9 10 package com.boyiz.gulimall.product.entity; @Data @TableName("pms_brand") public class BrandEntity implements Serializable { @NotNull(message = "修改必须指定ID",groups = {UpdateGroup.class}) //JSR303分组校验 @Null(message = "新增无需指定ID",groups = {AddGroup.class}) @TableId private Long brandId; }
Controller 中需要校验的参数Bean前添加 @Valid 开启校验功能,紧跟在校验的Bean后添加一个BindingResult,BindingResult封装了前面Bean的校验结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @PostMapping("/") public Result save (@Valid User user , BindingResult bindingResult) { if (bindingResult.hasErrors()) { Map<String , String> map = new HashMap<>(); bindingResult.getFieldErrors().forEach( (item) -> { String message = item.getDefaultMessage(); String field = item.getField(); map.put( field , message ); }); return Result.build( 400 , "非法参数 !" , map); } return Result.ok(); }
分组解决校验 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ## 两个空接口 public interface AddGroup {} public interface UpdateGroup {} ## 定义校验顺序,如果AddGroup组失败,则UpdateGroup组不会再校验 @GroupSequence({AddGroup.class, UpdateGroup.class}) public interface Group {} ⚠️## controller中要使用 @Validated @RequestMapping("/save") public R save(@Validated({AddGroup.class}) @RequestBody BrandEntity brand){ brandService.save(brand); return R.ok(); }
自定义校验注解 自定义一个校验注解@ListValue 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 package com.boyiz.common.validator.group; @Documented @Target({ElementType.METHOD, ElementType.FIELD, ElementType.ANNOTATION_TYPE, ElementType.CONSTRUCTOR, ElementType.PARAMETER, ElementType.TYPE_USE}) ⚠️ @Constraint(validatedBy = {ListValueConstraintValidator.class}) //指定自定义校验器 @Retention(RUNTIME) public @interface ListValue { //获取ValidationMessages.properties中的值 String message() default "{com.boyiz.common.validator.group.ListValue.message}"; Class<?>[] groups() default {}; Class<? extends Payload>[] payload() default {}; int[] vals() default {}; } ############################################################################################### 一个标注(annotation) 是通过@interface关键字来定义的. 这个标注中的属性是声明成类似方法 的样式的. 根据Bean Validation API 规范的要求: message属性, 这个属性被用来定义默认得消息模版, 当这个约束条件被验证失败的时候,通过 此属性来输出错误信息。 groups 属性, 用于指定这个约束条件属于哪(些)个校验组. 这个的默认值必须是Class<?>类型数组。 payload 属性, Bean Validation API 的使用者可以通过此属性来给约束条件指定严重级别. 这个属性并不被API自身所使用。 除了这三个强制性要求的属性(message, groups 和 payload) 之外, 还添加了一个属性用来指定所要求的值. 此属性的名称vals在annotation的定义中比较特殊, 如果只有这个属性被赋值了的话, 那么, 在使用此annotation到时候可以忽略此属性名称. 另外, 我们还给这个annotation标注了一些元标注( meta annotatioins): @Target({ METHOD, FIELD, ANNOTATION_TYPE }): 表示此注解可以被用在方法, 字段或者 annotation声明上。 @Retention(RUNTIME): 表示这个标注信息是在运行期通过反射被读取的. @Constraint(validatedBy = ListValueConstraintValidator.class): 指明使用哪个校验器(类) 去校验使用了此标注的元素. @Documented: 表示在对使用了该注解的类进行javadoc操作到时候, 这个标注会被添加到 javadoc当中.
在 src/main/resources 目录下创建一个名为 ValidationMessages.properties 的文件
1 com.boyiz.common.validator.group.ListValue.message = 必须使用指定数值
在实体类中使用
1 2 3 4 public class BrandEntity implements Serializable { ⚠️ @ListValue(vals={0,1},groups = {AddGroup.class, UpdateStatusGroup.class}) private Integer showStatus; }
创建约束校验器
@Constraint(validatedBy = ListValueConstraintValidator.class): 指明使用哪个校验器(类) 去校验使用了此标注的元素.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class ListValueConstraintValidator implements ConstraintValidator<ListValue, Integer> { private Set<Integer> set = new HashSet<>(); //初始化方法 @Override public void initialize(ListValue constraintAnnotation) { //ConstraintValidator.super.initialize(constraintAnnotation); int[] vals = constraintAnnotation.vals(); for (int val : vals) { set.add(val); } } //判断是否教研成功 /** * @param integer 需要校验的值 * @param constraintValidatorContext * @return */ @Override public boolean isValid(Integer integer, ConstraintValidatorContext constraintValidatorContext) { return set.contains(integer); } }
ElasticSearch
Docker安装 下载镜像文件
1 2 docker pull elasticsearch:7.4.2 存储和检索数据 docker pull kibana:7.4.2 可视化检索数据
创建实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 mkdir -p /mydata/elasticsearch/config mkdir -p /mydata/elasticsearch/data echo "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml chmod -R 777 /mydata/elasticsearch/ #保证权限 docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \ -e "discovery.type=single-node" \ -e ES_JAVA_OPTS="-Xms64m -Xmx512m" \ -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \ -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \ -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \ -d elasticsearch:7.4.2 特别注意: -e ES_JAVA_OPTS="-Xms64m -Xmx256m" 测试环境下,设置 ES 的初始内存和最大内存,否则导致过大启动ES失败。
安装Kibana
1 2 3 4 docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.56.10:9200 -p 5601:5601 \ -d kibana:7.4.2 http://192.168.56.10:9200 改为自己虚拟机/服务器的地址
基本概念 Index(索引) 动词,相当于 MySQL 中的 insert;
名词,相当于 MySQL 中的 Database 2、Type(类型)
Type(类型) 已弃用 在 Index(索引)中,可以定义一个或多个类型。
类似于 MySQL 中的 Table,每一种类型的数据放在一起;
Document(文档) 保存在某个索引(Index)下,某种类型(Type)的一个数据(Document),文档是 JSON 格式,Document 就像是 MySQL 中的某个 Table 里面的内容;
Field(字段) 每行数据有多个字段field,表示多列
倒排索引 机制 Elasticsearch 中的索引实际上就是所谓的倒排索引,它是所有搜索引擎工作的机制。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 假如在ES中存在这样三条记录: { "_id": 1, "log": "Oscar fourteen", } { "_id": 2, "log": "Tom fourteen kinds flowers", } { "_id": 3, "log": "Oscar fourteen flowers", }
Term Posting list Oscar [1, 3] fourteen [1, 2, 3] flowers [2, 3] kinds [2] Tom [2]
集群的概念
节点Node: 一个Elasticsearch实例,即为一个节点
集群Cluster: 一个或者多个节点共同协作,即组成一个集群
集群中所有的节点具有相同的cluster.name
集群中的一个节点会被选举为主节点master,临时管理集群级别的变更,如新增或删除节点,新建或删除索引等
集群中每个节点都知道文档存在于哪个节点上,每个节点都可以转发请求到真正存储数据的节点上
作为用户,我们可以访问任意节点(称作请求节点),请求节点负责收集各节点返回的数据,并聚合、处理后返回客户端
集群状态
1 使用/_cluster/health接口,可以获取当前集群的状态信息
分词
一个 tokenizer (分词器)接收一个字符流,将之分割为独立的 tokens (词元,通常是独立的单词),然后输出 tokens 流。
例如,whitespace tokenizer 遇到空白字符时分割文本。它会将文本 “Quick brown fox! “ 分割为 [Quick , brown , fox! ]。该 tokenizer (分词器)还负责记录各个 term (词条)的顺序或 position 位置(用于 phrase 短语和 word proximity 词近邻查询),以及 term (词条)所代表的原始 word (单词)的 start (起始)和 end (结束)的 character offsets (字符偏移量)(用于高亮显示搜索的内容)。Elasticsearch 提供了很多内置的分词器,可以用来构建 custom analyzers(自定义分词器)。
ik分词器 注意:不能用默认 elasticsearch-plugin install xxx.zip 进行自动安装
对应es版本进行安装
1 2 进入elasticsearch挂载的plugins目录 对压缩包进行解压
自定义分词器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 修改ik插件目录中的 IKAnalyzer.cfg.xml xxx/plugins/ik/config/IKAnalyzer.cfg.xml <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict"></entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> ⚠️<entry key="remote_ext_dict"> http://192.168.128.130/fenci/myword.txt </entry> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties> 然后重启 es 服务器 更新完成后,es 只会对新增的数据用新词分词。历史数据是不会重新分词的。如果想要历史数据重新分词。需要执行: POST my_index/_update_by_query?conflicts=proceed
Elasticsearch-Rest-Client 9300: TCP
spring-data-elasticsearch:transport-api.jar;
springboot版本不同,transport-api.jar 不同,不能适配es版本
7.x已经不建议使用,8以后就要废弃
9200: HTTP
选择 Elasticsearch-Rest-Client(elasticsearch-rest-high-level-client)
SpingBoot整合使用
1 2 3 4 5 6 ##依赖导入 <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.4.2</version> </dependency>
编写配置,在容器中注入一个RestHighLevelClient
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @Configuration public class ElasticSearchConfig { @Bean public RestHighLevelClient esRestClient() { RestHighLevelClient client = new RestHighLevelClient( RestClient.builder(new HttpHost("39.107.96.120", 9200, "http"))); return client; } public static final RequestOptions COMMON_OPTIONS; static { RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder(); // builder.addHeader("Authorization", "Bearer " + TOKEN); // builder.setHttpAsyncResponseConsumerFactory( // new HttpAsyncResponseConsumerFactory // .HeapBufferedResponseConsumerFactory(30 * 1024 * 1024 * 1024)); COMMON_OPTIONS = builder.build(); } }
_cat
1 2 3 4 GET /_cat/nodes :查看所有节点 GET /_cat/health : 查看 es 健康状况 GET /_cat/master :查看主节点 GET /_cat/indices :查看所有索引,相当于show databases
索引一个文档(保存)
1 2 3 4 5 6 7 8 PUT customer/external/1 { "name": "John Doe" } ⚠️注意 PUT 和 POST 都可以, POST新增,如果不指定id,会自动生成id。指定id 就会修改这个数据,并新增版本号。 PUT可以新增可以修改。PUT必须指定id;由于PUT需要指定id,我们一般都用来做修改操作,不指定id会报错。
查询文档
更新文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 POST customer/external/1/_update { "doc":{ "name": "John Doew" } } 或者 POST customer/external/1 { "name": "John Doe2" } 或者 PUT customer/external/1 { "name": "John Doe" } 不同: POST 操作会对比源文档数据,如果相同不操作,文档version不增加; PUT 操作总会将数据重新保存并增加 version 版本; 带_update 对比元数据如果一样就不进行任何操作。 根据场景; 对于大并发更新,不带 update 对于大并发查询偶尔更新,带 update 对比更新,重新计算分配规则。 更新同时增加属性 POST customer/external/1/_update { "doc": { "name": "Jane Doe", "age": 20 } } PUT 和 POST 不带_update 也可以
删除文档&索引
1 2 DELETE customer/external/1 DELETE customer
bulk 批量 API
bulk API 以此按顺序执行所有的 action(动作)。如果一个单个的动作因任何原因而失败, 它将继续处理它后面剩余的动作。当 bulk API 返回时,它将提供每个动作的状态(与发送的顺序相同),所以您可以检查是否一个指定的动作是不是失败了。
1 2 3 4 5 6 7 8 9 10 11 POST customer/external/_bulk {"index":{"_id":"1"}} {"name": "John Doe" } {"index":{"_id":"2"}} {"name": "Jane Doe" } 语法格式: { action: { metadata }} { request body } #两行为一对 { action: { metadata }} { request body }
JVM性能监控 虚拟机:VM Stack
描述的是JAVA方法执行的内存模型,每个方法在执行的时候都会创建一个栈帧, 用于存储局部变量表,操作数栈,动态链接,方法接口等信息
局部变量表存储了编译期可知的各种基本数据类型、对象引用
线程请求的栈深度不够会报StackOverflowError异常
栈动态扩展的容量不够会报OutOfMemoryError异常
虚拟机栈是线程隔离的,即每个线程都有自己独立的虚拟机栈
本地方法:Native Stack
本地方法栈类似于虚拟机栈,只不过本地方法栈使用的是本地方法
堆:Heap
堆
所有的对象实例以及数组都要在堆上分配。堆是垃圾收集器管理的主要区域,也被称为“GC 堆”;也是我们优化最多考虑的地方。
堆可以细分为:
新生代
Eden空间
FromSurvivor空间
ToSurvivor空间
老年代
永久代/元空间
Java8 以前永久代,受 jvm 管理,java8 以后元空间,直接使用物理内存。因此, 默认情况下,元空间的大小仅受本地内存限制。
垃圾回收
jvisualvm Java9以后不自带,需自行下载Visual VM,监控内存泄露,跟踪垃圾回收,执行时内存、cpu 分析,线程分析…
安装插件Visual GC方便查看 gc
压力测试 性能指标
响应时间(Response Time: RT)
响应时间指用户从客户端发起一个请求开始,到客户端接收到从服务器端返回的响应结束,整个过程所耗费的时间。
HPS(Hits Per Second) :每秒点击次数,单位是次/秒。
TPS(Transaction per Second):系统每秒处理交易数,单位是笔/秒。
QPS(Query per Second):系统每秒处理查询次数,单位是次/秒。
对于互联网业务中,如果某些业务有且仅有一个请求连接,那么 TPS=QPS=HPS,一般情况下用 TPS 来衡量整个业务流程,用 QPS 来衡量接口查询次数,用 HPS 来表示对服务器单击请求。
无论TPS、QPS、HPS,此指标是衡量系统处理能力非常重要的指标,越大越好,根据经验,一般情况下:
金融行业:1000TPS~50000TPS,不包括互联网化的活动
保险行业:100TPS~100000TPS,不包括互联网化的活动
制造行业:10TPS~5000TPS
互联网电子商务:10000TPS~1000000TPS
互联网中型网站:1000TPS~50000TPS
互联网小型网站:500TPS~10000TPS
最大响应时间(Max Response Time) 指用户发出请求或者指令到系统做出反应(响应) 的最大时间。
最少响应时间(Mininum ResponseTime)指用户发出请求或者指令到系统做出反应(响 应)的最少时间。
90%响应时间(90% Response Time) 是指所有用户的响应时间进行排序,第 90%的响应时间。
从外部看,性能测试主要关注如下三个指标
吞吐量:每秒钟系统能够处理的请求数、任务数。
响应时间:服务处理一个请求或一个任务的耗时。
错误率:一批请求中结果出错的请求所占比例。
JMeter Address Already in use 错误解决 windows 本身提供的端口访问机制的问题。
cmd 中,用 regedit 命令打开注册表
在 HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters 下,
右击 parameters,添加一个新的 DWORD,名字为 MaxUserPort
然后双击 MaxUserPort,输入数值数据为 65534,基数选择十进制(如果是分布式运 行的话,控制机器和负载机器都需要这样操作哦)
修改配置完毕之后记得重启机器才会生效
官方地址
缓存
哪些数据适合放入缓存?
即时性、数据一致性要求不高的
访问量大且更新频率不高的数据(读多,写少)
1 2 3 4 5 6 data = cache.load(id);//从缓存加载数据 if(data == null){ data = db.load(id);//从数据库加载数据 cache.put(id,data);//保存到 cache 中 } return data;
⚠️注意:在开发中,凡是放入缓存中的数据我们都应该指定过期时间,使其可以在系统即使没有主动更新数据也能自动触发数据加载进缓存的流程;避免业务崩溃导致的数据永久不一致问题。
整合Redis 1 2 3 4 5 6 7 8 9 10 11 <!--引入redis--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> 配置文件中配置redis信息 spring: redis: host: *.*.*.* port: 6379
使用 RedisTemplate 操作 redis 1 2 3 4 5 6 7 8 9 10 11 12 @Autowired StringRedisTemplate stringRedisTemplate; @Test public void testRedis(){ ValueOperations<String, String> ops = stringRedisTemplate.opsForValue(); //保存 ops.set("hello","world"); //查询 String hello = ops.get("hello"); System.out.println(hello); }
缓存失效问题 缓存穿透
缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致 *缓存在某一时刻同时失效 *,请求全部转发到 DB,DB 瞬时压力过重雪崩。
解决:
缓存击穿
缓存数据一致性 保证一致性模式 双写模式 失效模式
写数据库后,删除缓存。
出现问题:一个线程先写数据库db-1,然后删除缓存;另一个线程接着写数据库db-2,还没来得写完,第三个线程就读取了数据库原db-1数据,并更新了缓存,因此数据库中存放的是db-2,而缓存中存放的是db-1。【脏数据问题】
无论是双写模式还是失效模式,都会存在缓存不一致的问题。即多个实例同时更新会出事。
如果是用户维度数据(订单数据,用户数据),这种并发几率非常小,不用考虑这个问题,缓存数据加上过期时间,每隔一段时间触发读的主动更新即可。
如果是菜单,商品介绍等基础数据,也可以去使用canal订阅binlog方式。
缓存数据 + 过期时间 也足够解决大部分业务对缓存的要求。
通过加锁保证并发读写,写写的时候按顺序排好队,读读无所谓。所以适合使用读写锁。(业务不关系脏数据,允许临时脏数据可忽略)
总结:
我们能放入缓存的数据本就不应该是实时性、一致性要求超高的。缓存的所有数据都有过期时间,数据过期下一次查询出发主动更新。
读写数据的时候,加上分布式读写锁。
遇到实时性、一致性要求高的数据,就应该查数据库,即使慢点。
改进方法
分布式锁 本地锁 1 2 3 4 5 6 7 加锁:只要是同一把锁,就能锁住需要这个锁的所有线程。 synchronized (this) :springboot所有的组件在容器中都是单例的。 本地锁:synchronized,JUC(Lock)只能锁住当前进程; 在分布式情况下,想要锁住所有,必须使用分布式锁
分布式锁阶段一 1 2 3 若程序异常导致未删除锁,可能会造成死锁 解决: 设置锁的过期时间
分布式锁阶段二 1 2 3 若程序在设置锁过期时间时出现异常,会致死锁 解决: 上锁和设置过期时间需为原子操作,setnx ex
分布式锁阶段三 1 2 3 删除锁时自己的锁已过期导致删掉后来加上的非自己的锁 解决: 占锁的时候,指定为uuid,当匹配是自己锁才删除
分布式锁阶段四 1 2 3 4 5 6 判断完uuid之后删锁时,锁正好已过期,后来者的锁加上被删掉 解决: 删除锁必须保证原子性《Lua脚本》 String script = "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end"; Integer lock1 = stringRedisTemplate.execute(new DefaultRedisScript<Integer>(script, Integer.class), Arrays.asList("lock"), uuid); ## 示例:http://redis.cn/commands/set.html
分布式锁最终阶段 1 2 3 保证加锁【占位+过期时间】和删除锁【判断+删除】的原子性。 存在的问题: 无法完成锁的自动续期,并且所有的加锁解锁操作必须配合lua脚本完成,过于繁琐。
Redisson分布式锁 官方文档
1 2 3 4 5 6 7 8 ## 导入依赖 <!-- 使用redisson作为所有分布式锁,分布式对象等功能框架--> <!-- https://mvnrepository.com/artifact/org.redisson/redisson --> <dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.17.1</version> </dependency>
编写配置类文件 ——教程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Configuration public class MyRedissonConfig { /** * 所有对Redisson的操作都是通过RedissonClient对象 * @return * @throws IOException */ @Bean(destroyMethod="shutdown") public RedissonClient redisson() throws IOException { //1、创建配置 Config config = new Config(); config.useSingleServer().setAddress("redis://39.107.96.120:6379"); //2、根据config创建出RedissonClient实例 return Redisson.create(config); } }
锁的说明——官方
可重入锁(Reentrant Lock) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 @ResponseBody @GetMapping("/hello") public String hello() { //获取一把锁,只要锁的名字相同,就是同一把锁 RLock lock = redisson.getLock("my-lock"); //加锁 lock.lock();//阻塞式等待,默认加的锁都是30s的时间 //1)锁的自动续期,如果业务超长,运行期间自动给锁续上新的30s。不用担心业务时间长,锁自动过期被删除。 //2)加锁的业务只要运行完成,就不会给当前锁续期,即使不手动解锁,锁默认在30s之后自动删除。 //lock.lock(10, TimeUnit.SECONDS);//10s自动解锁,自动解锁时间一定要大于业务执行时间。 //问题:lock.lock(10, TimeUnit.SECONDS);在锁时间到了以后,不会自动续期。 //1. 如果我们传递了超时时间,就发送给redis执行脚本,进行占锁,默认超时就是我们指定的时间 //2. 如果我们未指定超时时间,就使用30 * 1000【lockWatchdogTimeout看门狗的默认时间】 // 只要占锁成功,就会启动一个定时任务【重新给锁设置过期时间,新的过期时间就是看门狗的默认时间】 // internalLockLeaseTime【看门狗的的时间】 / 3 ,也就是10s。每隔10s都会自动再次续期,续成30s //最佳实战:lock.lock(30, TimeUnit.SECONDS);省掉了整个续期操作,手动操作。将解锁时间设大一些 为30s try { System.out.println("加锁成功,指定业务代码...." + Thread.currentThread().getId()); Thread.sleep(30000); } catch (Exception e) { } finally { //解锁 假设解锁代码没有运行,redisson会不会出现死锁————不会。 System.out.println("释放锁..." + Thread.currentThread().getId() ); lock.unlock(); } return "hello"; }
读写锁(ReadWriteLock) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 /** * 保证一定能读到最新数据,修改期间,写锁是一个排它锁(互斥锁、独享锁),读锁是一个共享锁 * 写锁没释放读锁必须等待 * 读 + 读 :相当于无锁,并发读,只会在Redis中记录好,所有当前的读锁。他们都会同时加锁成功 * 写 + 读 :必须等待写锁释放 * 写 + 写 :阻塞方式 * 读 + 写 :有读锁。写也需要等待 * 只要有写的锁都必须等待 */ @ResponseBody @GetMapping("/write") public String writeValue() { RReadWriteLock lock = redisson.getReadWriteLock("wr-lock"); String s = ""; RLock rLock = lock.writeLock();//改数据加写锁 try { rLock.lock(); System.out.println("写锁加锁成功..." + Thread.currentThread().getId()); s = UUID.randomUUID().toString(); Thread.sleep(30000); redisTemplate.opsForValue().set("writeValue",s); } catch (InterruptedException e) { e.printStackTrace(); } finally { rLock.unlock(); System.out.println("写锁释放成功..." + Thread.currentThread().getId()); } return s; } @ResponseBody @GetMapping("/read") public String readValue() { RReadWriteLock lock = redisson.getReadWriteLock("wr-lock"); String s = ""; RLock rLock = lock.readLock();//读数据加读锁 try { rLock.lock(); System.out.println("读锁加锁成功..." + Thread.currentThread().getId()); Thread.sleep(30000); s = redisTemplate.opsForValue().get("writeValue"); } catch (Exception e) { e.printStackTrace(); } finally { rLock.unlock(); System.out.println("读锁释放成功..." + Thread.currentThread().getId()); } return s; }
信号量(Semaphore) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 /** * 车库停车 * 3车位 * 信号量也可以做分布式限流 */ @GetMapping(value = "/park") @ResponseBody public String park() throws InterruptedException { RSemaphore park = redisson.getSemaphore("park"); park.acquire(); //获取一个信号、获取一个值,占一个车位 boolean flag = park.tryAcquire(); if (flag) { //执行业务 } else { return "error"; } return "ok=>" + flag; } @GetMapping(value = "/go") @ResponseBody public String go() { RSemaphore park = redisson.getSemaphore("park"); park.release(); //释放一个信号 return "ok"; } 可以理解为信号量是存储在redis中的一个数字,当这个数字大于0时,即可以调用 release() 方法增加数量,也可以调用 acquire() 方法减少数量,但是当调用 release()之后小于0的话方法就会阻塞,直到数字大于0
闭锁(CountDownLatch) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 /** * 放假、锁门 * 5个班,全部走完,我们才可以锁大门 * 分布式闭锁 */ @GetMapping(value = "/lockDoor") @ResponseBody public String lockDoor() throws InterruptedException { RCountDownLatch door = redisson.getCountDownLatch("door"); door.trySetCount(5); door.await(); //等待闭锁完成 return "放假了..."; } @GetMapping(value = "/gogogo/{id}") @ResponseBody public String gogogo(@PathVariable("id") Long id) { RCountDownLatch door = redisson.getCountDownLatch("door"); door.countDown(); //计数-1 return id + "班的人都走了..."; }
Spring Cache
spring从3.1开始定义了Cache、CacheManager接口来统一不同的缓存技术。并支持使用JCache(JSR-107)注解简化开发。
每次调用需要缓存功能的方法时,spring会检查指定参数的指定的目标方法是否已经被调用过;如果有就直接从缓存中获取方法调用后的结果,如果没有就调用方法并缓存结果后返回给用户,下次调用直接从缓存中获取。
1 2 3 4 5 <!-- 引入SpringCache缓存--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-cache</artifactId> </dependency>
1 2 3 4 5 6 7 //开启缓存功能 @EnableCaching public class GulimallProductApplication { public static void main(String[] args) { SpringApplication.run(GulimallProductApplication.class, args); } }
1 2 3 4 5 #配置文件中设置 #配置redis作为缓存 spring.cache.type=redis #设置redis的key的ttl,单位:毫秒 spring.cache.redis.time-to-live= 3600000
编写配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Configuration @EnableCaching public class MyCacheConfig { /** * 会导致配置文件中的设置失效 * @return */ @Bean RedisCacheConfiguration redisCacheConfiguration(){ RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig(); //设置缓存以Json格式存储 config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer())); config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer())); config = config.entryTtl(Duration.ofMillis(300000));//设置失效时间 config = config.computePrefixWith(CacheKeyPrefix.prefixed("CACHE_"));//设置前缀 //默认缓存空值 return config; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 /** * @CacheEvict:失效模式 * @Caching:同时进行多种缓存操作 * @CacheEvict (value = "XXX",allEntries = true ):删除某个分区下的所有数据,失效模式 * @同一类型的数据可以指定为同一个分区 * @CachePut:双写模式 */ // @Caching(evict = { // @CacheEvict(value = "category", key = "'getLevel1Categorys'"), // @CacheEvict(value = "category", key = "'getCatalogJson'") // }) // @CacheEvict(value = "category", key = "'getLevel1Categorys'") // @CacheEvict(value = "category",allEntries = true ) //删除category分区中所有数据 // 每个缓存数据都需要指定放入哪个名字的缓存中【缓存的分区,按照业务类型分】 // value:缓存分区名, key:缓存数据的键,字符串加上单引号, // ex:key = "'level1Categorys'" ,设置方法名:key = "#root.method.name 1. 每一个需要缓存的数据我们都来指定要放到那个名字的缓存。【缓存的分区(按照业务划分)】 2. @Cacheable({"category"}):表示当前方法的结果需要缓存,如果缓存中有,方法不用调用。如果缓存中没有,会调用方法,并将方法的结果放入缓存。 3. 默认行为 1)如果缓存中有,方法不用调用 2)key默认自动生成:缓存的名字::SimpleKey [](自动生成key的值) 3)缓存的value的值:默认使用jdk序列换机制。将序列化后的数据存到redis。 4)默认ttl时间是-1。 4. 自定义 1)指定生成缓存使用的key: key属性指定,接收一个SpEL表达式 SpEL语法详细:https://docs.spring.io/spring-framework/docs/5.3.19-SNAPSHOT/reference/html/integration.html#cache 2)指定缓存数据的存活时间: 配置文件中修改ttl 3)将数据保存为json格式: 查看源码,自定义RedisCacheConfiguration配置类进行修改 @Cacheable(value = {"category"},key = "#root.method.name")
缓存注解的说明 :
@Cacheable:触发将数据保存到缓存的操作
@CacheEvict:触发将数据从缓存中删除的操作
@CachePut:不影响方法执行更新缓存
@Caching:组合以上多个操作
@CacheConfig:在类级别共享缓存的相同配置
原理说明:【源码分析】
1 2 3 4 5 CacheAutoConfiguration -> RedisCacheConfiguration -> 自动配置了缓存管理器RedisCacheManager -> 初始化所有的缓存 -> 每个缓存解决使用什么配置 -> 如果redisCacheConfiguration有就用已有的,没有就用默认配置 -> 想改缓存的配置,只需要给容器中放一个RedisCacheConfiguration即可 -> 就会应用到当前 RedisCacheManager管理的所有缓存分区中
SpringCache原理与不足:
1)读模式
缓存穿透:查询一个null数据。
解决方案:缓存空数据,可通过spring.cache.redis.cache-null-values=true
缓存击穿:大量并发进来同时查询一个正好过期的数据。
解决方案:加锁 ? 默认是无加锁的。
使用 sync = true 来解决击穿问题,只有@Cacheable有sync
缓存雪崩:大量的key同时过期。
解决:加随机时间。可通过spring.cache.redis.time-to-live=3600000
2)写模式:(缓存与数据库一致)
3)总结:
常规数据(读多写少,即时性,一致性要求不高的数据,完全可以使用Spring-Cache)
写模式(只要缓存的数据有过期时间就足够了)
特殊数据:特殊设计
多线程 初始化线程的 4 种方式
继承Thread
实现Runnable接口
实现Callable接口 + FutureTask
线程池
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 public class ThreadTest { public static ExecutorService service = Executors.newFixedThreadPool(10); public static void main(String[] args) throws ExecutionException, InterruptedException { //1、继承Thread Thread01 thread01 = new Thread01(); thread01.start(); //2、实现Runnable接口 Runnable01 runnable01 = new Runnable01(); new Thread(runnable01).start(); //3、实现Callable接口 + FutureTask FutureTask<Integer> futureTask = new FutureTask<>(new Callable01()); new Thread(futureTask).start(); Integer integer = futureTask.get();//阻塞等待整个线程执行完成,获取返回结果 //4、线程池 //我们以后业务代码里面,以上三种启动线程的方式都不用。【将所有的多线程异步任务都交给线程池执行】 //当前系统中池只有一两个,每个异步任务,提交给线程池让他自己去执行就行 service.execute(new Runnable01()); //原生的线程池 ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 200, 10, TimeUnit.SECONDS, new LinkedBlockingDeque<>(10000), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy()); } public static class Thread01 extends Thread { @Override public void run() { System.out.println("当前线程:"+Thread.currentThread().getId()); int i = 10 /2; System.out.println("运行结果:" + i); } } public static class Runnable01 implements Runnable { @Override public void run() { System.out.println("当前线程:"+Thread.currentThread().getId()); int i = 10 /2; System.out.println("运行结果:" + i); } } public static class Callable01 implements Callable<Integer> { @Override public Integer call() throws Exception { System.out.println("当前线程:"+Thread.currentThread().getId()); int i = 10 /2; System.out.println("运行结果:" + i); return i; } } } 总结: 方式 1 和方式 2 不能得到返回值,方式3 可以得到返回值。 方式 1 和方式 2 和方式 3 不利于控制服务器中的线程资源。会导致服务器资源耗尽。 方式 4 可以控制资源,比较稳定,也可以获取执行结果,并捕获异常。
线程池 优点
降低资源的消耗: 通过重复利用已经创建好的线程降低线程的创建和销毁带来的损耗。
提高响应速度:因为线程池中的线程数没有超过线程池的最大上限时, 有的线程处于等待分配任务的状态, 当任务来时无需创建新的线程就能执行。
提高线程的可管理性:线程池会根据当前系统特点对池内的线程进行优化处理, 减少创建和销毁线程带来的系统开销。 无限的创建和销毁线程不仅消耗系统资源, 还降低系统的稳定性, 使用线程池进行统一分配 。
常见的 4 种线程池
newCachedThreadPool :创建一个可缓存线程池, 如果线程池长度超过处理需要, 可灵活回收空闲线程, 若无可回收, 则新建线程。
newFixedThreadPool:创建一个定长线程池, 可控制线程最大并发数, 超出的线程会在队列中等待。
newScheduledThreadPool:创建一个定长线程池, 支持定时及周期性任务执行。
newSingleThreadExecutor:创建一个单线程化的线程池, 它只会用唯一的工作线程来执行任务, 保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行
线程池七大参数说明
int corePoolSize:核心线程数[一直存在,除非设置allowCoreThreadTimeOut];线程池创建好以后就准备就绪的线程数量,就等待来接受异步任务去执行。
int maximumPoolSize:最大线程数量;控制资源并发
long keepAliveTime:存活时间;如果当前的线程数量大于核心数量。 释放空闲的线程(keepAliveTime-corePoolSize)。只要线程空闲大于指定的keepAliveTime。
TimeUnit unit:时间单位;
BlockingQueue workQueue:阻塞队列;如果任务有很多,就会将目前多的任务放在队列里面。只要有线程空闲,就会去队列里面取出新的任务继续执行。
ThreadFactory threadFactory:线程的创建工厂;
RejectedExecutionHandler handler:如果队列满了,按照我们指定的拒绝策略拒绝执行任务。
线程池工作顺序
线程池创建,准备好 core 数量的核心线程,准备接受任务
新的任务进来,用 core 准备好的空闲线程执行。
core 满了,就将再进来的任务放入阻塞队列中。空闲的 core 就会自己去阻塞队 列获取任务执行
阻塞队列满了,就直接开新线程执行,最大只能开到 max 指定的数量
max 都执行好了。Max-core 数量空闲的线程会在 keepAliveTime 指定的时间后自动销毁。最终保持到 core 大小
如果线程数开到了 max 的数量,还有新任务进来,就会使用 reject 指定的拒绝策 略进行处理
所有的线程创建都是由指定的 factory 创建的。
面试: 一个线程池 core 7; max 20 ,queue:50,100 并发进来怎么分配?
CompletableFuture 异步编排
在 Java 8 中, 新增加了一个包含 50 个方法左右的类: CompletableFuture, 提供了非常强大的Future 的扩展功能, 可以帮助我们简化异步编程的复杂性, 提供了函数式编程的能力, 可以通过回调的方式处理计算结果, 并且提供了转换和组合 CompletableFuture 的方法。CompletableFuture 类实现了 Future 接口, 所以你还是可以像以前一样通过get方法阻塞或者轮询的方式获得结果, 但是这种方式不推荐使用。
CompletableFuture 和 FutureTask 同属于 Future 接口的实现类, 都可以获取线程的执行结果。
创建异步操作
runXxxx 没有返回结果
supplyXxx 可以获取返回结果的
Executor 可以传入自定义的线程池, 否则就用默认的线程池 。
1 2 3 4 5 6 7 8 9 10 public class ThreadTest { public static ExecutorService executor = Executors.newFixedThreadPool(10); public static void main(String[] args) throws ExecutionException, InterruptedException { CompletableFuture<Void> future = CompletableFuture.runAsync(() -> { System.out.println("当前线程:" + Thread.currentThread().getId()); int i = 10 / 2; System.out.println("运行结果:" + i); }, executor); } }
方法完成后的感知
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class CompletableFutureTest { public static ExecutorService service = Executors.newFixedThreadPool(10); public static void main(String[] args) throws ExecutionException, InterruptedException { CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> { System.out.println("当前线程:" + Thread.currentThread().getId()); int i = 10 / 0; System.out.println("运行结果:" + i); return i; }, executor).whenComplete((res,exception) -> { //虽然能得到异常信息,但是没法修改返回数据 System.out.println("异步任务成功完成了...结果是:" + res + "异常是:" + exception); }).exceptionally(throwable -> { //可以感知异常,同时返回默认值 return 10; }); } }
handle,方法完成后的处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class CompletableFutureTest { public static ExecutorService service = Executors.newFixedThreadPool(10); public static void main(String[] args) throws ExecutionException, InterruptedException { CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> { System.out.println("当前线程:" + Thread.currentThread().getId()); int i = 10 / 2; System.out.println("运行结果:" + i); return i; }, executor).handle((result,thr) -> { if (result != null) { return result * 2; } if (thr != null) { System.out.println("异步任务成功完成了...结果是:" + result + "异常是:" + thr); return 0; } return 0; }); } }
线程串行化方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 /** * 1.thenRunAsync:不能获取到上一步的执行结果,无返回值 * .thenRunAsync(() -> { * System.out.println("任务2启动了..."); * }, service); * 2.thenAcceptAsync:能接收上一步结果,无返回值 * .thenAcceptAsync(res -> { * System.out.println("任务2启动了..." + res); * }, service); * 3.thenApplyAsync:能接收上一步结果,有返回值 * .thenApplyAsync(res -> { * System.out.println("任务2启动了..." + res); * return "hello" + res; * }, service); */ public class CompletableFutureTest { public static ExecutorService service = Executors.newFixedThreadPool(10); public static void main(String[] args) throws ExecutionException, InterruptedException { CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> { System.out.println("当前线程:" + Thread.currentThread().getId()); int i = 10 / 4; System.out.println("运行结果:" + i); return i; }, service).thenApplyAsync(res -> { System.out.println("任务2启动了..." + res); return "hello" + res; }, service); } }
两个都完成再执行第三个
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public class CompletableFutureTest { public static ExecutorService service = Executors.newFixedThreadPool(10); public static void main(String[] args) throws ExecutionException, InterruptedException { CompletableFuture<Object> future01 = CompletableFuture.supplyAsync(() -> { System.out.println("plan1:" + Thread.currentThread().getId()); int i = 10 / 2; System.out.println("plan1_over:" + i); return i; }, executor); CompletableFuture<Object> future02 = CompletableFuture.supplyAsync(() -> { System.out.println("plan2:" + Thread.currentThread().getId()); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } int i = 10 / 2; System.out.println("plan2_over:" + i); return "hello " + i; }, executor); //组合plan1和plan2,完成plan1和plan2之后开始第三个任务,无法感知结果 future01.runAfterBothAsync(future02, () -> { System.out.println("plan3_start"); }, executor); //可感知结果, void accept(T t, U u); future01.thenAcceptBothAsync(future02, (f1, f2) -> { System.out.println("plan3_start"); System.out.println("plan1 result:" + f1); System.out.println("plan2 result:" + f2); }, executor); //再进阶,合并多个任务,可指定返回值 // R apply(T t, U u); CompletableFuture<String> future03 = future01.thenCombineAsync(future02, (f1, f2) -> { System.out.println("plan3_start"); return "result:" + f1 + "--> " + f2; }, executor); System.out.println(future03.get()); } }
完成任意一个 future,执行任务3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public class CompletableFutureTest { public static ExecutorService service = Executors.newFixedThreadPool(10); public static void main(String[] args) throws ExecutionException, InterruptedException { CompletableFuture<Object> future01 = CompletableFuture.supplyAsync(() -> { System.out.println("plan1:" + Thread.currentThread().getId()); int i = 10 / 2; System.out.println("plan1_over:" + i); return i; }, executor); CompletableFuture<Object> future02 = CompletableFuture.supplyAsync(() -> { System.out.println("plan2:" + Thread.currentThread().getId()); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } int i = 10 / 2; System.out.println("plan2_over:" + i); return "hello " + i; }, executor); //不感知结果,无返回值 future01.runAfterEitherAsync(future02, () -> { System.out.println("plan3_start"); //future2设置Thread.sleep()测试效果。 },executor); //感知结果,无返回值 future01.acceptEitherAsync(future02, (res) -> { System.out.println("plan3_start"); //future2设置Thread.sleep()测试效果。 System.out.println("res:"+ res); },executor); //感知结果,也有返回值 CompletableFuture<String> future03 = future01.applyToEitherAsync(future02, (res) -> { System.out.println("plan3_start"); //future2设置Thread.sleep()测试效果。 return res + " plan3"; }, executor); System.out.println(future03.get()); } }
多任务组合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class CompletableFutureTest { public static ExecutorService service = Executors.newFixedThreadPool(10); public static void main(String[] args) throws ExecutionException, InterruptedException { CompletableFuture<String> futureImg = CompletableFuture.supplyAsync(()->{ System.out.println("查询图片信息"); return "hello.jpg"; },executor); CompletableFuture<String> futureAttr = CompletableFuture.supplyAsync(()->{ try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("查询属性信息"); return "黑色 128G"; },executor); CompletableFuture<String> futureDesc = CompletableFuture.supplyAsync(()->{ System.out.println("查询介绍信息"); return "Huawei"; },executor); CompletableFuture<Void> allOf = CompletableFuture.allOf(futureImg, futureAttr, futureDesc); allOf.get(); //等待所有结果完成 System.out.println("结束。。。"); System.out.println(futureImg.get()); System.out.println(futureAttr.get()); System.out.println(futureDesc.get()); CompletableFuture<Object> anyOf = CompletableFuture.anyOf(futureImg, futureAttr, futureDesc); anyOf.get(); //只要有一个完成 System.out.println(anyOf.get()); }
认证服务 开通阿里云的短信服务
进入阿里云的短信服务
开通短信服务
申请短信模板,需要等待审核
获取accessKeyID、accessKeySecret、signName、templateCode
整合短信服务
引入 spring-cloud-starter-alicloud-oss 依赖
application.properties中配置属性
1 2 3 4 5 6 7 8 spring: cloud: alicloud: sms: access-key-i-d: 阿里云头像下拉选中得到 access-key-secret: 阿里云头像下拉选中得到 sign-name: 阿里云申请的签名 template-code: 阿里云申请的模板
封装发送验证码的接口
在测试类中调用接口测试
发送验证码并防刷 要解决的问题:
在页面上检查元素时,暴露了验证码的请求路径,那么别人拿到这个请求路径就可以无限制的发送验证码。
尽管我们设置了60秒之后才能再次发送验证码,但是只要刷新页面,还是可以重新发送验证码,因此需要设置验证码防刷功能,即使刷新页面仍然需要等待60秒之后才能再次发送验证码。
验证码在注册时需要再次校验,因此生成验证码之后,需要重新存起来
我们需要设置验证码的过期时间,即验证码在5分钟内有效,即设置redis的过期时间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @GetMapping("/sendcode") public R sendCode(@RequestParam("phone") String phone) { //TODO 1、接口防刷 String redisCode = redisTemplate.opsForValue(). get(AuthServerConstant.SMS_CODE_CACHE_PREFIX + phone); if (!StringUtils.isEmpty(redisCode)) { Long time = Long.parseLong(redisCode.split("_")[1]); if (System.currentTimeMillis() - time < 60000) { return R.error(BizCodeEnume.SMS_CODE_EXCEPTION.getCode(), BizCodeEnume.SMS_CODE_EXCEPTION.getMessage()); } } //2、验证码的再次校验,redis: key-》phone,value-》code //sms:code:17777777777 -> 123456 //加上系统时间判断防止被刷验证码 String code = UUID.randomUUID().toString().substring(0, 6); //redis缓存验证码,防止同一个phone在60s内再次发送 redisTemplate.opsForValue(). setIfAbsent(AuthServerConstant.SMS_CODE_CACHE_PREFIX + phone, code + "_" + System.currentTimeMillis(), 10, TimeUnit.MINUTES); thridPartFeignService.sendCode(phone, code); return R.ok(); }
OAuth2.0
微博社交登录
登录新浪微博开发平台进行登录:https://open.weibo.com/,创建个人信息,创建新应用。
API文档中的授权流程 :
2.1、引导需要授权的用户到如下地址:
https://api.weibo.com/oauth2/authorize?client_id=YOUR_CLIENT_ID&response_type=code&redirect_uri=YOUR_REGISTERED_REDIRECT_URI YOUR_REGISTERED_REDIRECT_URI/?code=CODE
https://api.weibo.com/oauth2/access_token?client_id=YOUR_CLIENT_ID&client_secret=YOUR_CLIENT_SECRET&grant_type=authorization_code&redirect_uri=YOUR_REGISTERED_REDIRECT_URI&code=CODE
测试得到access_token :
3.1、引导用户到达如下地址:client_id=App Key,redirect_uri=重定向地址
https://api.weibo.com/oauth2/authorize?client_id=AppKey&response_type=code&redirect_uri=重定向地址
用户同意授权后,就会获得一个code,拿到code我们就可以换取access_token
3.3、换取Access Token:
使用获得的Access Token调用API
整合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @GetMapping("/weibo/success") public R weibo(@RequestParam("code") String code) throws Exception { //https://api.weibo.com/oauth2/authorize?client_id=YOUR_CLIENT_ID&response_type=code&redirect_uri=YOUR_REGISTERED_REDIRECT_URI //https://api.weibo.com/oauth2/access_token?client_id=YOUR_CLIENT_ID&client_secret=YOUR_CLIENT_SECRET&grant_type=authorization_code&redirect_uri=YOUR_REGISTERED_REDIRECT_URI&code=CODE Map<String, String> map = new HashMap<>(); map.put("client_id", "7******5"); map.put("client_secret", "6c84***********b8a"); map.put("grant_type", "authorization_code"); map.put("redirect_uri", "http://gulimall.com/oauth2/weibo/success"); map.put("code", code); //根据code换取access_token HttpResponse response = HttpUtils.doPost("https://api.weibo.com", "/oauth2/access_token", "post", new HashMap<>(), map, new HashMap<>()); if (response.getStatusLine().getStatusCode() == 200) { //获取到access_token String json = EntityUtils.toString(response.getEntity()); SocialUser socialUser = JSON.parseObject(json, SocialUser.class); //判断用户是否已注册 //登录或注册,调用member远程方法 R r = memberFeignService.authLogin(socialUser); return R.ok().put("data", r.get("data")); } else { return R.error(BizCodeEnume.USER_AUTHLOGIN_EXCEPTION.getCode(),BizCodeEnume.USER_AUTHLOGIN_EXCEPTION.getMessage()); } }
分布式session问题
在单体应用中,跨页面共享数据,我们可以使用session来存储,在浏览器打开到关闭期间,session 中存储的数据都能取出来,假如我们现在将登录的用户放在session中会有什么问题 ?
存在问题:
问题1:session不能跨不同域名进行共享,即使不是分布式情况下,只是使用不用服务部署不同域名:
问题2:session不同步问题
即使是同域名的情况下,在分布式部署下,会员服务不可能只部署到一台服务器上去,可能多台服务器同时都有会员服务,假设浏览器第一次登录请求发给了1号服务器,那么1号服务器就把我们的用户保存了,由于我们是分布式集群环境,那么下一次请求可能会落到2号服务器,2号服务器并没有用户数据。
分布式Session情况下,Session不同步的四种解决方案 :
Sesison不能跨不同域名进行共享的解决方案:
现在的问题是在auth.gulimal.com域名下会保存cookie,但是在gulimall.com中却没有,我们希望只要在子域名下的cookie,父域名也能感知到。
子域:gulimall.com,auth.gulimall.com,order.gulimall.com
父域:gulimall.com
使用JWT 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 public final class JwtUtil { /** * 这个秘钥是防止JWT被篡改的关键,随便写什么都好,但决不能泄露 */ private final static String secretKey = "gulimallJWT"; /** * 过期时间设置,这个配置随业务需求而定 */ private final static Duration expiration = Duration.ofHours(5); /** * 生成JWT * * @param userName 用户名 * @return JWT */ public static String generate(String userName) { // 过期时间 Date expiryDate = new Date(System.currentTimeMillis() + expiration.toMillis() * 10); return Jwts.builder() .setSubject(userName) // 将userName放进JWT .setIssuedAt(new Date()) // 设置JWT签发时间 .setExpiration(expiryDate) // 设置过期时间 .signWith(SignatureAlgorithm.HS512, secretKey) // 设置加密算法和秘钥 .compact(); } /** * 解析JWT * * @param token JWT字符串 * @return 解析成功返回Claims对象,解析失败返回null */ public static Claims parse(String token) { // 如果是空字符串直接返回null if (StringUtils.isEmpty(token)) { return null; } // 这个Claims对象包含了许多属性,比如签发时间、过期时间以及存放的数据等 Claims claims = null; // 解析失败了会抛出异常,所以我们要捕捉一下。token过期、token非法都会导致解析失败 try { claims = Jwts.parser() .setSigningKey(secretKey) // 设置秘钥 .parseClaimsJws(token) .getBody(); } catch (JwtException e) { // 这里应该用日志输出,为了演示方便就直接打印了 System.err.println("解析失败!"); } return claims; } }
登录成功后将JWT封装在实体类中返回
1 //返回jwt memberEntity.setToken(JwtUtil.generate(memberEntity.getUsername()+"_"+memberEntity.getId()));
使用时
ThreadLocal的作用就是同一个线程共享数据,同一个线程:拦截器 -> controller -> service -> dao
拿到JWT解析,获取用户ID,封装ThreadLocal
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @Component public class LoginUserInterceptor extends HandlerInterceptorAdapter { public static ThreadLocal<MemberResponseVo> loginUser = new ThreadLocal<>(); @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { String uri = request.getRequestURI(); AntPathMatcher antPathMatcher = new AntPathMatcher(); boolean match = antPathMatcher.match("/order/order/status/**", uri); boolean match1 = antPathMatcher.match("/payed/**", uri); if (match || match1) { return true; } // 从请求头中获取token字符串 String jwt = request.getHeader("Authorization"); // 解析失败就提示用户登录 Claims claims = JwtUtil.parse(jwt); if (claims != null) { MemberResponseVo memberResponseVo = new MemberResponseVo(); memberResponseVo.setId( Long.parseLong( claims.get("sub").toString().split("_")[1])); loginUser.set(memberResponseVo); return true; } else { throw new RRException("当前用户未登录"); } } }
消息队列 RabbitMQ RabbitMQ简介
RabbitMQ是一个由erlang开发的AMQP(Advanved Message Queue Protocol)的开源实现。
Message消息:消息是不具名的,它由消息头和消息体组成。消息体是不透明的,而消息头则由一系列的可选属性组成,
Publisher消息的生产者:也是一个向交换器发布消息的客户端应用程序。
Exchange交换器 :用来接收生产者发送的消息并将这些消息路由给服务器中的队列。
Queue消息队列 :用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。
Binding绑定 :用于消息队列和交换器之间的关联。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。Exchange 和Queue的绑定可以是多对多的关系。
Connection网络连接:比如一个TCP连接。
Channel信道 :多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的TCP连接内的虚拟连接,AMQP 命令都是通过信道发出去的,不管是发布消息、订阅队列还是接收消息,这些动作都是通过信道完成。因为对于操作系统来说建立和销毁 TCP 都是非常昂贵的开销,所以引入了信道的概念,以复用一条 TCP 连接。
Consumer消息的消费者:表示一个从消息队列中取得消息的客户端应用程序。
Virtual Host虚拟主机:表示一批交换器、消息队列和相关对象。虚拟主机是共享相同的身份认证和加密环境的独立服务器域。每个 vhost 本质上就是一个 mini 版的 RabbitMQ 服务器,拥有自己的队列、交换器、绑定和权限机制。vhost 是 AMQP 概念的基础,必须在连接时指定,RabbitMQ 默认的 vhost 是 / 。
Broker:表示消息队列服务器实体
Exchange类型 AMQP 中消息的路由过程和 Java 开发者熟悉的 JMS 存在一些差别,AMQP 中增加了 Exchange 和Binding 的角色。生产者把消息发布到 Exchange 上,消息最终到达队列并被消费者接收,而 Binding 决定交换器的消息应该发送到那个队列。
Exchange分发消息时根据类型的不同分发策略有区别,目前共四种类型:direct、fanout、topic、headers
direct 直接路由:
fanout 广播:
topic 发布订阅:
Spring Boot整合RabbitMQ 1)引入 spring-boot-starter-amqp 依赖
2)在application.yml中配置属性
1 2 3 spring.rabbitmq.host=192.168.xx.xx spring.rabbitmq.port=5672 spring.rabbitmq.virtual-host=/
3)主启动类上开启RabbitMQ的相关功能,使用 @EnableRabbit 注解
4)测试创建交换机,队列,将队列绑定交换机
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 @Slf4j @RunWith(SpringRunner.class) @SpringBootTest public class GulimallOrderApplicationTests { @Autowired AmqpAdmin amqpAdmin; @Autowired RabbitTemplate rabbitTemplate; @Test public void createExchange () { DirectExchange directExchange = new DirectExchange ("hello-java-exchange" ,true ,false ); amqpAdmin.declareExchange(directExchange); log.info("Exchange[{}]创建成功" , "hello-java-exchange" ); } @Test public void createQueue () { Queue queue = new Queue ("hello-java-queue" ,true ,false ,false ); amqpAdmin.declareQueue(queue); log.info("Queue[{}]创建成功" , "hello-java-queue" ); } @Test public void createBinding () { Binding binding = new Binding ("hello-java-queue" , Binding.DestinationType.QUEUE, "hello-java-exchange" , "hello.java" , null ); amqpAdmin.declareBinding(binding); log.info("Binding[{}]创建成功" , "hello-java-binding" ); } }
5)测试发送消息
1 2 3 4 5 6 7 @Test public void sendMessage () { String msg = "hello world" ; rabbitTemplate.convertAndSend("hello.java.exchange" ,"hello.java" , msg); log.info("消息发送完成{}" ,msg); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 @RestController public class RabbitController { @Autowired RabbitTemplate rabbitTemplate; @GetMapping("/sendMq") public String sendMq (@RequestParam(value = "num",defaultValue = "10") Integer num) { for (int i = 0 ; i < num; i++) { if (i % 2 == 0 ) { OrderReturnReasonEntity reasonEntity = new OrderReturnReasonEntity (); reasonEntity.setCreateTime(new Date ()); reasonEntity.setId(1L ); reasonEntity.setName("退货原因" +i); rabbitTemplate.convertAndSend("hello.java.exchange" ,"hello.java" , reasonEntity); } else { OrderEntity orderEntity = new OrderEntity (); orderEntity.setOrderSn(UUID.randomUUID().toString()); rabbitTemplate.convertAndSend("hello.java.exchange" ,"hello.java" , orderEntity); } } return "ok" ; } }
注意:如果发送对象,使用JSON序列化机制,进行消息转换,否则发送出去的就是字节数据。
1 2 3 4 5 6 7 @Configuration public class MyRabbitConfig { @Bean public MessageConverter messageConverter () { return new Jackson2JsonMessageConverter (); } }
6)监听队列中的消息 :【进行消费】
监听消息:使用@RabbitListener;主启动类必须有@EnableRabbit
Queue:可以很多人都来监听。只要收到消息,队列删除消息,而且只能有一个收到此消息
场景:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @RabbitListener(queues = {"hello-java-queue"}) @Service("orderItemService") public class OrderItemServiceImpl extends ServiceImpl <OrderItemDao, OrderItemEntity> implements OrderItemService { @RabbitHandler public void recieveMessage (Message message, OrderReturnReasonEntity content, Channel channel) throws InterruptedException { System.out.println("接收到消息..." + message); System.out.println("内容:" +content); } @RabbitHandler public void recieveMessage2 (OrderEntity content) { System.out.println("内容..." +content); } }
RabbitMQ消息确认机制 使用消息传递代理(例如RabbitMQ)的系统是分布式的。由于不能保证发送消息可以到达对等方或被其成功处理,因此发布者和使用者都需要一种机制来进行传递和处理确认。
保证消息不丢失,可靠抵达,可以使用事务消息,性能下降250倍,为此引入确认机制
可靠抵达 - ConfirmCallback 只要消息抵达Broker就ack=true
• 设置 PublisherConfirms(true) 选项,开启confirmcallback 。
1 2 开启发送者确认模式 spring.rabbitmq.publisher-confirms=true
• 消息只要被 broker 接收到就会执行 confirmCallback,如果是 cluster 模式,需要所有broker 接收到才会调用 confirmCallback。
• CorrelationData:用来表示当前消息唯一性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @Configuration public class MyRabbitConfig { @Autowired RabbitTemplate rabbitTemplate; @PostConstruct public void initRabbitTemplate () { rabbitTemplate.setConfirmCallback(new RabbitTemplate .ConfirmCallback() { @Override public void confirm (CorrelationData correlationData, boolean ack, String cause) { System.out.println("correlationData--》" +correlationData +"ack--》" +ack + "causer--》" +cause); } }); } }
可靠抵达 - ReturnCallback • confrim 模式只能保证消息到达 broker,不能保证消息准确投递到目标 queue 里。在有些业务场景下,我们需要保证消息一定要投递到目标 queue 里,此时就需要用到 return 退回模式。
• 这样如果未能投递到目标 queue 里将调用 returnCallback ,可以记录下详细到投递数据,定期的巡检或者自动纠错都需要这些数据。
1 2 3 4 # 开启发送端消息抵达队列的确认 spring.rabbitmq.publisher-returns=true # 只要抵达队列,以异步发送优先回调我们这个returnconfirm spring.rabbitmq.template.mandatory=true
• 被 broker 接收到只能表示 message 已经到达服务器,并不能保证消息一定会被投递到目标 queue 里。所以需要用到接下来的returnCallback
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 @Configuration public class MyRabbitConfig { @Autowired RabbitTemplate rabbitTemplate; @PostConstruct public void initRabbitTemplate () { rabbitTemplate.setConfirmCallback(new RabbitTemplate .ConfirmCallback() { @Override public void confirm (CorrelationData correlationData, boolean ack, String cause) { System.out.println("correlationData--》" +correlationData +"ack--》" +ack + "causer--》" +cause); } }); rabbitTemplate.setReturnCallback(new RabbitTemplate .ReturnCallback() { @Override public void returnedMessage (Message message, int replyCode, String replyText, String exchange, String routingKey) { System.out.println("Fail Message[" +message+"]-->replyCode[" +replyCode+"]-->replyText[" +replyText+"]-->exchange[" +exchange+"]-->routingKey[" +routingKey+"]" ); } }); } }
可靠抵达 - Ack消息确认机制 消费者获取到消息,成功处理,可以回复Ack给Broker
默认自动ack,消息被消费者收到,就会从broker的queue中移除;
queue无消费者,消息依然会被存储,直到消费者消费;
消费者收到消息,默认会自动ack,
如果无法确定此消息是否被处理完成,或者成功处理,我们可以开启手动ack模式
消息确认的类型 :
channel.basicAck(deliveryTag, multiple)
consumer处理成功后,通知broker删除队列中的消息,如果设置multiple=true,表示支持批量确认机制以减少网络流量。true )——则表示前面未确认的5,6,7投递也一起确认处理完毕。false )——则仅表示deliveryTag=8的消息已经成功处理。
channel.basicNack(deliveryTag, multiple, requeue)
consumer处理失败后,
例如:有值为5,6,7,8 deliveryTag的投递。
channel.basicReject(deliveryTag, requeue)
相比channel.basicNack,除了没有multiple 批量确认机制 之外,其他语义完全一样。
1 2 # 设置为手动ack方式 spring.rabbitmq.listener.simple.acknowledge-mode=manual
此时监听队列中的消息,并设置手动确认:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 @RabbitListener(queues = {"hello-java-queue"}) @Service("orderItemService") public class OrderItemServiceImpl extends ServiceImpl <OrderItemDao, OrderItemEntity> implements OrderItemService { @RabbitHandler public void recieveMessage (Message message, OrderReturnReasonEntity content, Channel channel) throws InterruptedException { byte [] body = message.getBody(); MessageProperties messageProperties = message.getMessageProperties(); System.out.println("消息处理完==>" + content.getName()); long deliveryTag = message.getMessageProperties().getDeliveryTag(); System.out.println("deliveryTag ==> " + deliveryTag); try { if (deliveryTag%2 == 0 ) { channel.basicAck(deliveryTag,false ); System.out.println("签收了货物..." + deliveryTag); } else { channel.basicNack(deliveryTag,false ,true ); System.out.println("没有签收了货物..." + deliveryTag); } } catch (IOException e) { e.printStackTrace(); } } @RabbitHandler public void recieveMessage2 (OrderEntity content) { System.out.println("接收消息..." +content); } }
消息的TTL(Time To Live)
消息的TTL就是消息的存活时间。
RabbitMQ可以对队列和消息分别设置TTL。
对队列设置就是队列没有消费者连着的保留时间,也可以对每一个单独的消息做单独的设置。超过了这个时间,我们认为这个消息就死了,称之为 死信
如果队列设置了,消息也设置了,那么会取小的值。所以一个消息如果被路由到不同的队 列中,这个消息死亡的时间有可能不一样(不同的队列设置)。这里单讲单个消息的 TTL,因为它才是实现延迟任务的关键。可以通过设置消息的expiration字段或者x- message-ttl属性来设置时间,两者是一样的效果。
Dead Letter Exchanges (DLX) 死信路由
一个消息在满足如下条件下,会进死信路由,记住这里是 路由 而不是 队列 , 一个路由可以对应很多队列。(什么是死信)
一个消息被Consumer拒收了,并且reject方法的参数里requeue是false。也就是说不 会被再次放在队列里,被其他消费者使用。(basic.reject/ basic.nack )requeue=false
上面的消息的TTL到了,消息过期了。
队列的长度限制满了。排在前面的消息会被丢弃或者扔到死信路由上
Dead Letter Exchange其实就是一种普通的exchange,和创建其他 exchange没有两样。只是在某一个设置Dead Letter Exchange的队列中有消息过期了,会自动触发消息的转发,发送到Dead Letter Exchange中去。
我们既可以控制消息在一段时间后变成死信,又可以控制变成死信的消息被路由到某一个指定的交换机,结合二者,其实就可以实现一个延时队列
手动ack&异常消息统一放在一个队列处理建议的两种方式
catch异常后,手动发送到指定队列 ,然后使用channel给rabbitmq确认消息已消费
给Queue绑定死信队列,使用nack(requque为false)确认消息消费失败
延时队列实现 场景:比如未付款订单,超过一定时间后,系统自动取消订单并释放占有物品。
设置队列过期时间 消息首先交给交换机,交换机按照路由键发给指定的队列,这个队列设置了过期时间,以及死信路由键,由于没有消费者这监听这个队列,当消息死了扔给指定的队列。
设置消息过期时间 发送消息的时候,单独为消息设置过期时间,消息经过交换机发给延时队列,由于没有消费者这监听这个队列,消息过期之后就会发给死信交换机,通过交换机发给指定的队列。
模拟关单简单方式 :
创建两个交换机 :user.order.delay.exchange 和 user.order.exchange ,这两个交换机各绑定了一个队列,其中死信队列:user.order.delay.queue 是没有消费者监听的,user.order.queue是有消费者监听的,当订单服务创建一个订单后会将消息发送给user.order.delay.exchange交换机,这个交换机经过指定的路由键order_delay发给user.order.delay.queue队列,由于队列的过期时间x-message-ttl=60000,即为1分钟,当1分钟之后,队列就会过期变为死信,交给x-dead-letter-exchange: user.order.exchange ,通过路由键x-dead-letter-routing-key: order 发给指定的队列user.order.queue。
模拟关单升级方式
消息创建成功后先按照 order.create.order 找到对应的交换机 orer-event-exchange,在按照 order.create.order 找到对应的队列 order.delay.queue ,这个队列是一个延时队列,设置了三个参数:x-dead-letter-exchange: order-event-exchange ,当队列中的消息经过x-message-ttl: 60000 时间后变成死信,然后通过x-dead-letter-routing-key: order.release.order找到这个队列order.release.order,将死信交给它 。
创建交换机,队列,以及绑定关系:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 @Configuration public class MyMQConfig { @Bean public Queue orderDelayOrderQueue () { Map<String, Object> arguments = new HashMap <>(); arguments.put("x-dead-letter-exchange" , "order-event-exchange" ); arguments.put("x-dead-letter-routing-key" , "order.release.order" ); arguments.put("x-message-ttl" , 120000 ); Queue queue = new Queue ("order.delay.queue" , true , false , false , arguments); return queue; } @Bean public Queue orderReleaseOrderQueue () { Queue queue = new Queue ("order.release.order.queue" , true , false , false ); return queue; } @Bean public Exchange orderEventExchange () { return new TopicExchange ("order-event-exchange" , true , false ); } @Bean public Binding orderCreateOrderBinding () { return new Binding ("order.delay.queue" , Binding.DestinationType.QUEUE, "order-event-exchange" , "order.create.order" , null ); } @Bean public Binding orderReleaseOrderBinding () { return new Binding ("order.release.order.queue" , Binding.DestinationType.QUEUE, "order-event-exchange" , "order.release.order" , null ); } @Bean public Binding orderReleaseOtherBingding () { return new Binding ("stock.release.stock.queue" , Binding.DestinationType.QUEUE, "order-event-exchange" , "order.release.other.#" , null ); } }
创建订单并给消息队列发送消息测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Controller public class HelloController { @Autowired RabbitTemplate rabbitTemplate; @ResponseBody @GetMapping("/test/createOrder") public String createOrderTest () { OrderEntity entity = new OrderEntity (); entity.setOrderSn(UUID.randomUUID().toString()); entity.setModifyTime(new Date ()); rabbitTemplate.convertAndSend("order-event-exchange" ,"order.create.order" ,entity); return "ok" ; } }
如何保证消息可靠性 消息丢失
• 做好容错方法(try-catch),发送消息可能会网络失败,失败后要有重试机制,可记录到数据库,采用定期扫描重发的方式
• 做好日志记录,每个消息状态是否都被服务器收到都应该记录
• 做好定期重发,如果消息没有发送成功,定期去数据库扫描未成功的消息进行重发
-
• publisher也必须加入确认回调机制,确认成功的消息,修改数据库消息状态。
自动ACK的状态下,消费者收到消息,但没来得及消息然后宕机
• 一定开启手动ACK,消费成功才移除,失败或者没来得及处理就noAck并重新入队
消息重复
消息消费成功,事务已经提交,ack时,机器宕机。导致没有ack成功,Broker的消息 重新由unack变为ready,并发送给其他消费者
消息消费失败,由于重试机制,自动又将消息发送出去
成功消费,ack时宕机,消息由unack变为ready,Broker又重新发送
• 消费者的业务消费接口应该设计为幂等性 的。比如扣库存有工作单的状态标志
• 使用防重表 (redis/mysql),发送消息每一个都有业务的唯一标识,处理过就不用处理
• rabbitMQ的每一个消息都有redelivered字段,可以获取是否是被重新投递过来的 ,而不是第一次投递过来的
消息积压
消费者宕机积压
消费者消费能力不足积压
发送者发送流量太大
• 上线更多的消费者,进行正常消费
• 上线专门的队列消费服务,将消息先批量取出来,记录数据库,离线慢慢处理
商城业务 - 订单业务
订单的创建与支付:
(1) 、 订单创建前需要预览订单, 选择收货信息等
订单确认流程
接口幂等性 接口幂等性就是用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用;比如说支付场景, 用户购买了商品支付扣款成功, 但是返回结果的时候网络异常, 此时钱已经扣了, 用户再次点击按钮, 此时会进行第二次扣款, 返回结果成功, 用户查询余额返发现多扣钱了, 流水记录也变成了两条,这就没有保证接口的幂等性。
哪些情况需要防止
① 用户多次点击按钮
什么情况下需要幂等,以 SQL 为例, 有些操作是天然幂等
① SELECT * FROM table WHER id=?,无论执行多少次都不会改变状态, 是天然的幂等。
幂等解决方案 token 机制 服务端提供了发送 token 的接口。 我们在分析业务的时候, 哪些业务是存在幂等问题的,就必须在执行业务前, 先去获取 token, 服务器会把 token 保存到 redis 中 。然后调用业务接口请求时, 把 token 携带过去, 一般放在请求头部。服务器判断 token 是否存在 redis 中, 存在表示第一次请求, 然后删除 token,继续执行业务。如果判断 token 不存在 redis 中, 就表示是重复操作, 直接返回重复标记给 client, 这样就保证了业务代码, 不被重复执行。
先删除 token 还是后删除 token?
先删除可能导致,业务确实没有执行,重试还带上之前 token,由于防重设计导致,请求还是不能执行。
token 获取、 比较和删除必须是原子性
redis.get(token) 、 token.equals、 redis.del(token)如果这两个操作不是原子, 可能导致高并发下, 都 get 到同样的数据, 判断都成功, 继续业务并发执行可以在 redis 使用 lua 脚本完成这个操作
1 if redis.call(‘get’, KEYS[1 ]) == ARGV[1 ] then return redis.call(‘del’, KEYS[1 ]) else return 0 end
锁机制 数据库悲观锁
数据库乐观锁 更新 的场景中,
业务层分布式锁
各种唯一约束 数据库唯一约束
redis set 防重 很多数据需要处理,只能被处理一次,比如我们可以计算数据的 MD5 将其放入 redis 的 set,每次处理数据,先看这个 MD5 是否已经存在,存在就不处理。
防重表 使用订单号 orderNo 做为去重表的唯一索引, 把唯一索引插入去重表, 再进行业务操作, 且他们在同一个事务中。 这个保证了重复请求时, 因为去重表有唯一约束, 导致请求失败, 避免了幂等问题。 这里要注意的是, 去重表和业务表应该在同一库中, 这样就保证了在同一个事务, 即使业务操作失败了, 也会把去重表的数据回滚。 这个很好的保证了数据一致性。之前说的 redis 防重也算
全局请求唯一 id 调用接口时, 生成一个唯一 id, redis 将数据保存到集合中(去重) ,存在即处理过。可以使用 nginx 设置每一个请求的唯一 id:proxy_set_header X-Request-Id $request_id
令牌防止多次提交表单
分布式事务 本地事务 数据库事务的几个特性: 原子性 、 一致性 、 隔离性和持久性, 简称就是 ACID;
原子性: 一系列的操作整体不可拆分, 要么同时成功, 要么同时失败
在以往的单体应用中, 我们多个业务操作使用同一条连接操作不同的数据表, 一旦有异常,我们可以很容易的整体回滚比如买东西业务, 扣库存, 下订单, 账户扣款, 是一个整体; 必须同时成功或者失败,一个事务开始, 代表以下的所有操作都在同一个连接里面。
Business: 我们具体的业务代码。Storage: 库存业务代码; 扣库存。Order: 订单业务代码; 保存订单。Account: 账号业务代码; 减账户余额
事务的隔离级别 READ UNCOMMITTED(读未提交):该隔离级别的事务会读到其它未提交事务的数据, 此现象也称之为脏读。
READ COMMITTED(读提交):一个事务可以读取另一个已提交的事务, 多次读取会造成不一样的结果, 此现象称为不可重复读问题, Oracle 和 SQL Server 的默认隔离级别。
REPEATABLE READ( 可重复读):该隔离级别是 MySQL 默认的隔离级别, 在同一个事务里, select 的结果是事务开始时时间点的状态, 因此, 同样的 select 操作读到的结果会是一致的, 但是, 会有幻读现象。 MySQL的 InnoDB 引擎可以通过 next-key locks 机制( 参考下文”行锁的算法”一节) 来避免幻读。
SERIALIZABLE( 序列化):在该隔离级别下事务都是串行顺序执行的, MySQL 数据库的 InnoDB 引擎会给读操作隐式加一把读共享锁, 从而避免了脏读、 不可重读复读和幻读问题
事务的传播行为 PROPAGATION_REQUIRED: 如果当前没有事务, 就创建一个新事务, 如果当前存在事务,就加入该事务, 该设置是最常用的设置。
PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。
PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
PROPAGATION_REQUIRES_NEW:创建新事务, 无论当前存不存在事务, 都创建新事务。
PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作, 如果当前存在事务, 就把当前事务挂起
PROPAGATION_NEVER:以非事务方式执行, 如果当前存在事务, 则抛出异常。
PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作。
本地事务在分布式下的问题
业务描述:创建好订单后,需要进行下单,下单完成后远程调用gulimall-ware库存服务,远程锁库存,库存锁定成功后又需要远程调用gulimall-member服务,远程扣减积分,而且整个过程是处在本地事务@Transactional中的,那么这样会出现怎么样的问题?本地事务能解决什么问题?
存在的问题:
订单服务连接的是订单数据库,这是一个连接,库存服务连接的是库存数据库,这是一个新的连接,会员服务链接的是会员数据库,这也是一个新的连接。远程调用实际上是一个新的连接,会员服务发生异常,库存服务是感知不到的,已经执行成功的请求是不能回滚的。
远程服务假失败:远程服务其实成功了,由于网络故障等没有返回,导致:订单回滚,库存却扣减
本地事务只能控制住在同一个连接中的异常,在分布式系统中,A服务远程调用B服务,B服务远程调用C服务,C服务远程调用D服务,任何一个远程服务出现问题,已经成功执行的远程服务没办法通过Transactional来实现事务的回滚,除非这几个服务不是远程服务,操作的是同一个数据库,在同一个连接内。
本地事务在分布式系统下,只能控制住自己数据库的回滚,控制不了其他服务的数据库的回滚。
分布式事务的问题:网络问题+分布式机器(数据库不是同一个)。
分布式事务理论 为什么有分布式事务
CAP 定理与 BASE 理论CAP 定理 CAP 原则又称 CAP 定理, 指的是在一个分布式系统中。
CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
分布式系统中实现一致性的 raft 算法、paxos。 http://thesecretlivesofdata.com/raft/
面临的问题
BASE 理论
基本可用(Basically Available)
软状态(Soft State)
最终一致性(Eventual Consistency)
强一致性、弱一致性、最终一致性
分布式事务常见解决方案 2PC 模式 数据库支持的 2PC【 2 phase commit 二阶提交】 , 又叫做 XA Transactions。其中,XA 是一个两阶段提交协议, 该协议分为以下两个阶段:
XA 协议比较简单, 而且一旦商业数据库实现了 XA 协议, 使用分布式事务的成本也比较低。
XA 性能不理想, 特别是在交易下单链路, 往往并发量很高, XA 无法满足高并发场景
XA 目前在商业数据库支持的比较理想, 在 mysql 数据库中支持的不太理想, mysql 的XA 实现, 没有记录 prepare 阶段日志, 主备切换回导致主库与备库数据不一致。
许多 nosql 也没有支持 XA, 这让 XA 的应用场景变得非常狭隘。
也有3PC,引入了超时机制(无论协调者还是参与者,在向对方发送请求后,若长时间未收到回应则做出相应处理)
柔性事务 - TCC 事务补偿型方案 刚性事务:遵循 ACID 原则,强一致性。
一阶段 prepare 行为: 调用 自定义 的 prepare 逻辑。
柔性事务 - 最大努力通知型方案 按规律进行通知,不保证数据一定能通知成功,但会提供可查询操作接口进行核对。这种方案主要用在与第三方系统通讯时,比如:调用微信或支付宝支付后的支付结果通知。这种方案也是结合 MQ 进行实现,例如:通过 MQ 发送 http 请求,设置最大通知次数。达到通 知次数后即不再通知。
案例:银行通知、商户通知等(各大交易业务平台间的商户通知:多次通知、查询校对、对账文件),支付宝的支付成功异步回调
柔性事务**-可靠消息 +**最终一致性方案(异步确保型) 实现:业务处理服务在业务事务提交之前,向实时消息服务请求发送消息,实时消息服务只 记录消息数据,而不是真正的发送。业务处理服务在业务事务提交之后,向实时消息服务确 认发送。只有在得到确认发送指令后,实时消息服务才会真正发送。
防止消息丢失:pulisher ,consumer 【手动 ack 】)
最终一致性库存解锁逻辑 在高并发场景下,库存的回滚使用 :柔性事务-最大努力通知型方案 或 柔性事务-可靠消息+最终一致性方案( 异步确保型)
商城业务:库存解锁 创建路由交换机和队列 gulimall-ware服务整合RabbitMQ
① 导入rabbitmq 依赖
库存锁定成功后,会根据路由键 stock.locked 根据交换机stock-event-exchange,交换机找到队列stock.delay.queue,并将消息发送到消息队列,由于这个队列是延时队列,50min之后队列中的消息变成死信,然后按照路由键stock.release根据交换机stock-event-exchange找到队列stock.release.stock.queue,将消息发送到该队列,然后接下来的解锁库存服务就来处理stock.release.stock.queue中的消息,因为这个队列中的信息都是超时的死信。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 @Configuration public class MyRabbitConfig { @Bean public MessageConverter messageConverter () { return new Jackson2JsonMessageConverter (); } @Bean public Exchange stockEventExchange () { return new TopicExchange ("stock-event-exchange" , true , false ); } @Bean public Queue stockReleaseStockQueue () { return new Queue ("stock.release.stock.queue" , true , false , false ); } @Bean public Queue stockDelayQueue () { Map<String, Object> args = new HashMap <>(); args.put("x-dead-letter-exchange" , "stock-event-exchange" ); args.put("x-dead-letter-routing-key" , "stock.release" ); args.put("x-message-ttl" , 240000 ); return new Queue ("stock.delay.queue" , true , false , false , args); } @Bean public Binding stockReleaseBinding () { return new Binding ("stock.release.stock.queue" , Binding.DestinationType.QUEUE, "stock-event-exchange" , "stock.release.#" , null ); } @Bean public Binding stockLockedBinding () { return new Binding ("stock.delay.queue" , Binding.DestinationType.QUEUE, "stock-event-exchange" , "stock.locked" , null ); } }
库存自动解锁 库存解锁的场景 :
步骤:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 @Override public void unlockStock (StockLockedTo stockLockedTo) { StockDetailTo detail = stockLockedTo.getDetail(); Long detailId = detail.getId(); WareOrderTaskDetailEntity wareOrderTaskDetailEntity = wareOrderTaskDetailService.getById(detailId); if (wareOrderTaskDetailEntity!=null ){ Long id = stockLockedTo.getId(); WareOrderTaskEntity wareOrderTaskEntity = wareOrderTaskService.getById(id); String orderSn = wareOrderTaskEntity.getOrderSn(); R r = orderFeignService.getOrderStatus(orderSn); if (r.getCode() == 0 ){ OrderVo data = r.getData(new TypeReference <OrderVo>() {}); if (data == null || data.getStatus() == OrderStatusEnum.CANCLED.getCode()){ if (wareOrderTaskDetailEntity.getLockStatus() == WareStatusEnum.LOCK_WARE.getCode()){ unLockStock(detail.getSkuId(), detail.getWareId(), detail.getSkuNum(), detailId); } } }else { throw new RuntimeException ("远程服务失败" ); } }else { } } private void unLockStock (Long skuId, Long wareId, Integer num, Long taskDetailId) { wareSkuDao.unLockStock(skuId, wareId, num); WareOrderTaskDetailEntity taskDetailEntity = new WareOrderTaskDetailEntity (); taskDetailEntity.setId(taskDetailId); taskDetailEntity.setLockStatus(WareStatusEnum.UNLOCK_WARE.getCode()); wareOrderTaskDetailService.updateById(taskDetailEntity); }
监听 stock.release.stock.queue 队列,对库存进行解锁:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @RabbitListener(queues = "stock.release.stock.queue") @Service public class StockReleaseListener { @Autowired WareSkuService wareSkuService; @RabbitHandler public void handleStockLockedRelease (StockLockedTo stockLockedTo, Message message, Channel channel) throws IOException { System.out.println("收到解锁库存的消息..." ); try { wareSkuService.unlockStock(stockLockedTo); channel.basicAck(message.getMessageProperties().getDeliveryTag(),false ); } catch (Exception e) { channel.basicReject(message.getMessageProperties().getDeliveryTag(),true ); } } }
定时关单和手动库存解锁 订单创建成功后,如果30分钟没有支付,那么系统就要自动取消订单
首先订单创建成功后,先给交换机发送一个消息(创建成功的订单消息),交换机通过路由键将消息发送给延时队列,消息30min之后过期,过期的消息会通过交换机和路由键发送给队列order.release.order.queue,从而让没有支付的订单消息关闭。
① 订单创建成功后就会给 order-event-exchange交换机发送消息 ,通过路由键发送给延时队列 order.delay.queue,延时队列中的消息一旦过过期就会通过交换机的路由键发送给 order.release.order.queue队列,从而实现关闭订单。
② 监听 @RabbitListener(queues = “order.release.order.queue”)这个队列中的消息,实现关闭订单功能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @RabbitListener(queues = "order.release.order.queue") @Service public class OrderCloseListener { @Autowired OrderService orderService; @RabbitHandler public void listener (OrderEntity orderEntity, Channel channel, Message message) throws IOException { System.out.println("收到过期的订单消息:准备关闭订单" + orderEntity.getOrderSn()); try { orderService.closeOrder(orderEntity); channel.basicAck(message.getMessageProperties().getDeliveryTag(), false ); } catch (IOException e) { channel.basicReject(message.getMessageProperties().getDeliveryTag(), true ); } } }
③ 库存解锁在订单解锁之后,只要订单解锁成功了,那么库存解锁时看订单已经关单了,库存就自动解锁了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Service @RabbitListener(queues = "stock.release.stock.queue") public class StockReleaseListener { @Autowired WareSkuService wareSkuService; @RabbitHandler public void handleStockLockedRelease (StockLockedTo stockLockedTo, Message message, Channel channel) throws IOException { System.out.println("订单关闭准备解锁库存..." ); try { wareSkuService.unlockStock(stockLockedTo); channel.basicAck(message.getMessageProperties().getDeliveryTag(),false ); } catch (Exception e) { channel.basicReject(message.getMessageProperties().getDeliveryTag(),true ); } } }
④ 但是还有一种情况,如果订单创建成功后由于机器卡顿,消息延迟等原因,订单还没解锁,库存解锁就先执行了,那么库存就没办法解锁了,因为已经解锁一次了,就不会走解锁逻辑了:
解决方法:除了订单创建完成后等待它自动解锁库存之外,我们在订单解锁成功后也应该主动的发送一个消息到交换机,交换机通过路由键order.release.other会将消息发送给stock.release.stock.queue队列,从而实现手动解锁库存。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Configuration public class MyMQConfig { @Bean public Binding orderReleaseOtherBingding () { return new Binding ("stock.release.stock.queue" , Binding.DestinationType.QUEUE, "order-event-exchange" , "order.release.other.#" , null ); } }
订单解锁成功后给交换机发送一个消息,交换机通过路由键将消息发送给 stock.release.stock.queue队列,监听这个队列实现库存的解锁:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Override public void closeOrder (OrderEntity entity) { OrderEntity orderEntity = getById(entity.getId()); if (orderEntity.getStatus() == OrderStatusEnum.CREATE_NEW.getCode()){ OrderEntity update = new OrderEntity (); update.setId(entity.getId()); update.setStatus(OrderStatusEnum.CANCLED.getCode()); this .updateById(update); OrderTo orderTo = new OrderTo (); BeanUtils.copyProperties(orderEntity, orderTo); try { rabbitTemplate.convertAndSend("order-event-exchange" , "order.release.other" , orderTo); } catch (Exception e) { } } }
1 2 3 4 5 6 7 8 9 10 @RabbitHandler public void handleOrderCloseRelease (OrderTo orderTo, Message message, Channel channel) throws IOException { System.out.println("订单关闭准备解锁库存..." ); try { wareSkuService.unlockStock(orderTo); channel.basicAck(message.getMessageProperties().getDeliveryTag(),false ); }catch (Exception e){ channel.basicReject(message.getMessageProperties().getDeliveryTag(),true ); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Transactional @Override public void unlockStock (OrderTo orderTo) { String orderSn = orderTo.getOrderSn(); WareOrderTaskEntity task = wareOrderTaskService.getOrderTaskByOrderSn(orderSn); Long id = task.getId(); List<WareOrderTaskDetailEntity> entities = wareOrderTaskDetailService.list( new QueryWrapper <WareOrderTaskDetailEntity>() .eq("task_id" , id) .eq("lock_status" , WareStatusEnum.LOCK_WARE.getCode())); for (WareOrderTaskDetailEntity entity : entities) { unLockStock(entity.getSkuId(), entity.getWareId() ,entity.getSkuNum(), entity.getId()); } }
商城业务 - 支付 支付宝开放平台
支付宝文档中心
支付宝沙箱
支付宝密钥工具
支付宝的通用配置类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 @ConfigurationProperties(prefix = "alipay") @Component @Data public class AlipayTemplate { public String app_id; public String merchant_private_key; public String alipay_public_key; public String notify_url; public String return_url; private String sign_type; private String charset; private String timeout = "2m" ; public String gatewayUrl; public String pay (PayVo vo) throws AlipayApiException { AlipayClient alipayClient = new DefaultAlipayClient (gatewayUrl, app_id, merchant_private_key, "json" , charset, alipay_public_key, sign_type); AlipayTradePagePayRequest alipayRequest = new AlipayTradePagePayRequest (); alipayRequest.setReturnUrl(return_url); alipayRequest.setNotifyUrl(notify_url); String out_trade_no = vo.getOut_trade_no(); String total_amount = vo.getTotal_amount(); String subject = vo.getSubject(); String body = vo.getBody(); alipayRequest.setBizContent("{\"out_trade_no\":\"" + out_trade_no + "\"," + "\"total_amount\":\"" + total_amount + "\"," + "\"subject\":\"" + subject + "\"," + "\"body\":\"" + body + "\"," + "\"timeout_express\":\"" + timeout + "\"," + "\"product_code\":\"FAST_INSTANT_TRADE_PAY\"}" ); String result = alipayClient.pageExecute(alipayRequest).getBody(); System.out.println("支付宝的响应:" + result); return result; } }
商城业务 - 秒杀功能 定时任务 - cron表达式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 特殊字符: ,:枚举; (cron="7,9,23 * * * * ?"):任意时刻的 7,9,23 秒启动这个任务; -:范围: (cron="7-20 * * * * ?"):任意时刻的 7-20 秒之间,每秒启动一次 *:任意; 指定位置的任意时刻都可以 /:步长; (cron="7/5 * * * * ?"):第 7 秒启动,每 5 秒一次; (cron="*/5 * * * * ?"):任意秒启动,每 5 秒一次; ?:(出现在日和周几的位置):为了防止日和周冲突,在周和日上如果要写通配符使用? (cron="* * * 1 * ?"):每月的 1 号,启动这个任务; L:(出现在日和周的位置)”, last:最后一个 (cron="* * * ? * 3L"):每月的最后一个周二 W: Work Day:工作日 (cron="* * * W * ?"):每个月的工作日触发 (cron="* * * LW * ?"):每个月的最后一个工作日触发 #:第几个 (cron ="* * * ? * 5#2"):每个月的第 2 个周 4
Spring boot整合定时任务
@EnableScheduling:开启其实任务
@Scheduled:开启一个定时任务
秒杀(高并发)系统关注的问题
服务单一职责 + 独立部署
秒杀链接加密
防止恶意攻击,模拟秒杀请求,1000次/s攻击。
防止链接暴露,自己工作人员,提前秒杀商品。
库存预热 + 快速扣减
秒杀读多血少。无需内次实时校验库存。我们库存预热,放到redis中。信号量控制进来秒杀的请求。
动静分离
nginx做好动静分离。保证秒杀和商品详情页的动态请求才打到后端的服务集群。使用CDN网络,分担本集群压力
恶意请求拦截
流量错峰
使用各种手段,将流量分担到更大宽度的时间点。比如验证码,加入购物车
限流&熔断&降级
前端限流+后端限流。限制次数,限制总量,快速失败降级运行,熔断隔离防止雪崩
队列削峰
1万个商品,每个1000件秒杀。双11所有秒杀成功的请求,进入队列,慢慢创建订单,扣减库存即可。
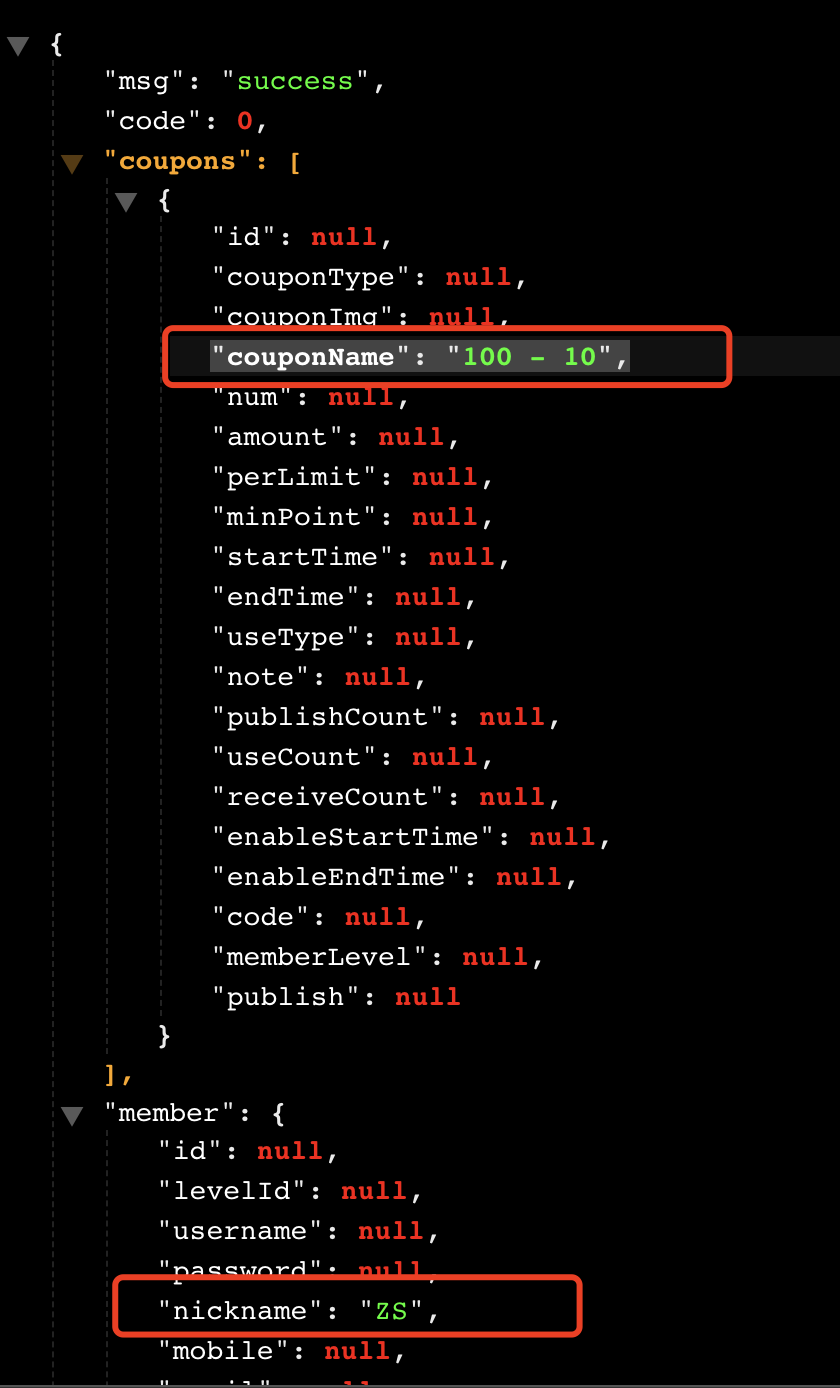
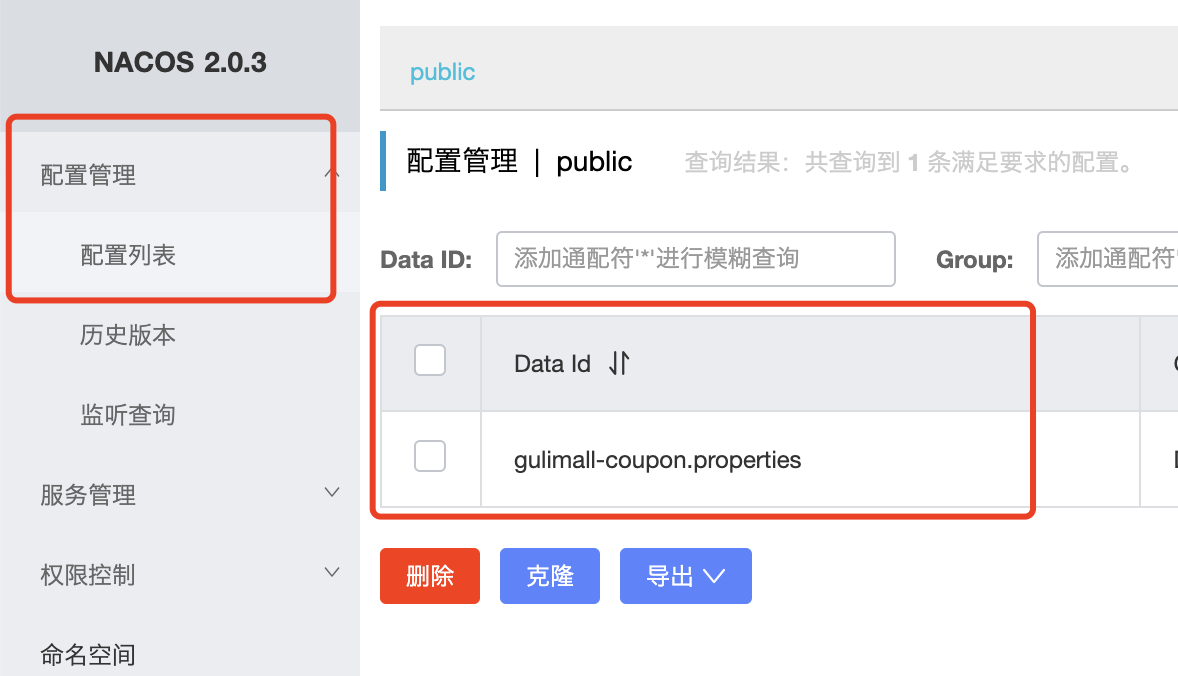
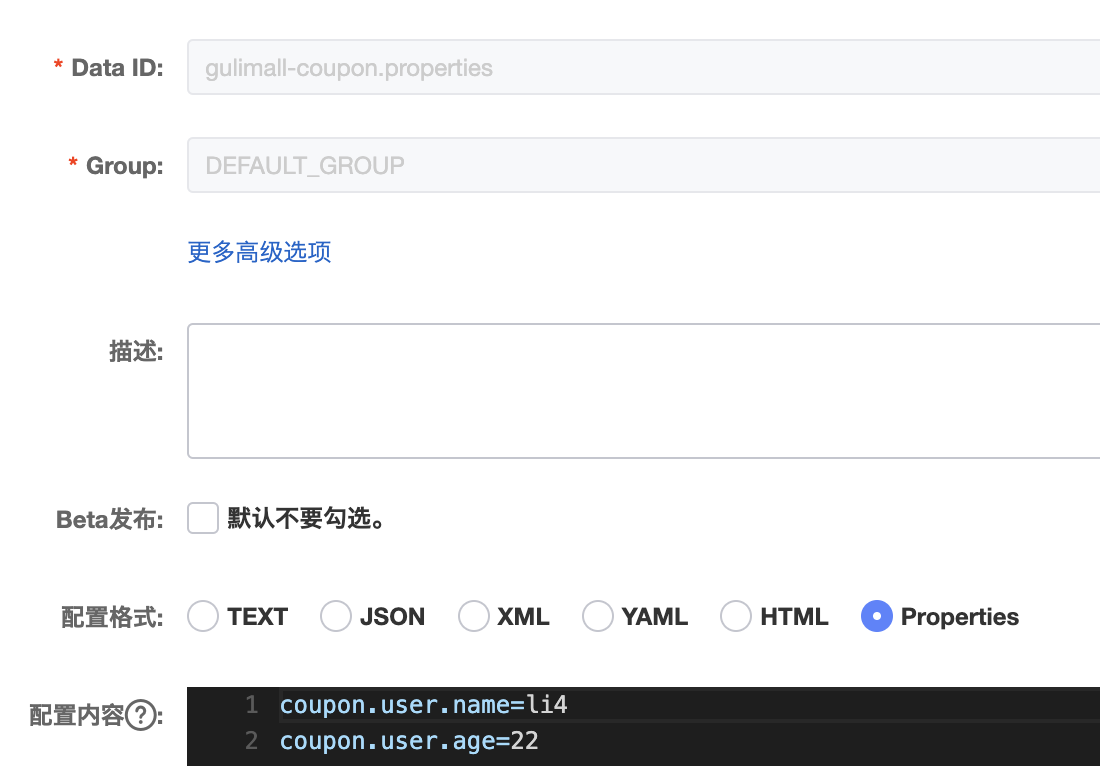
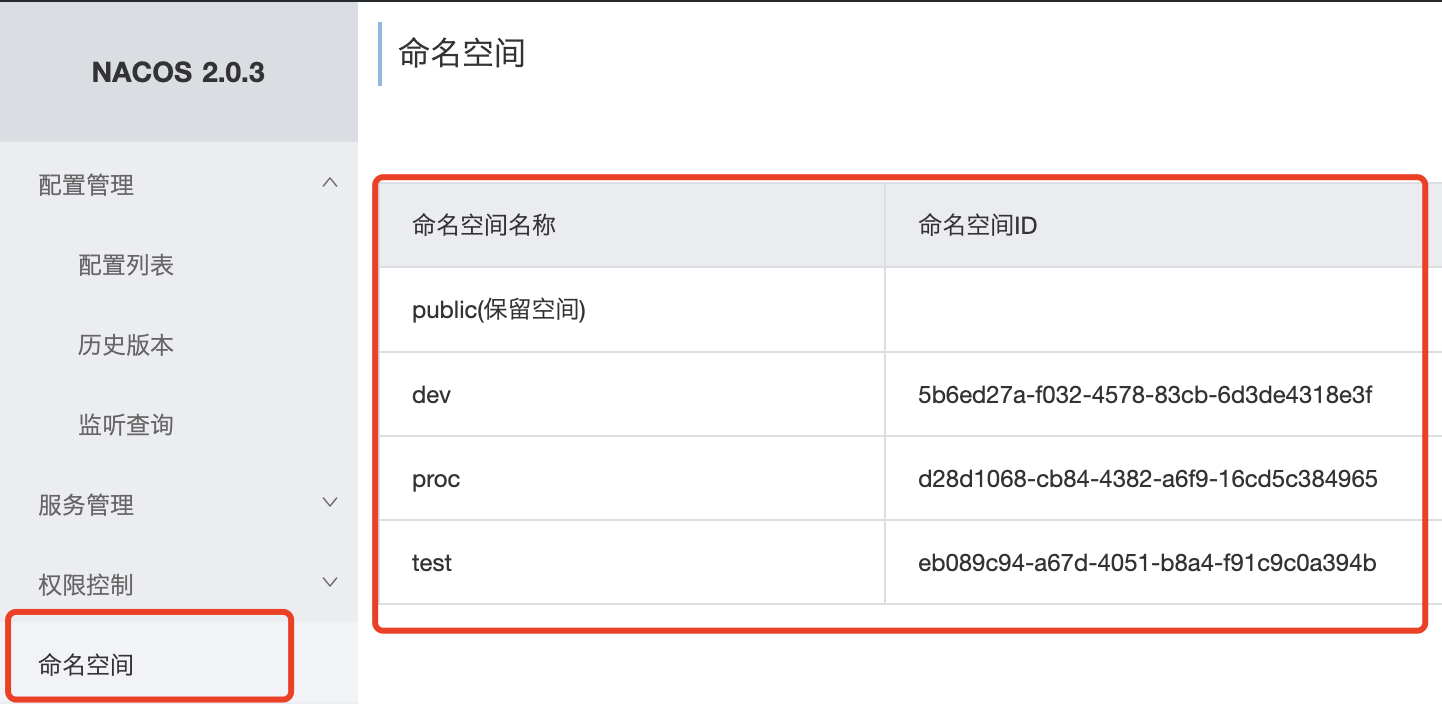
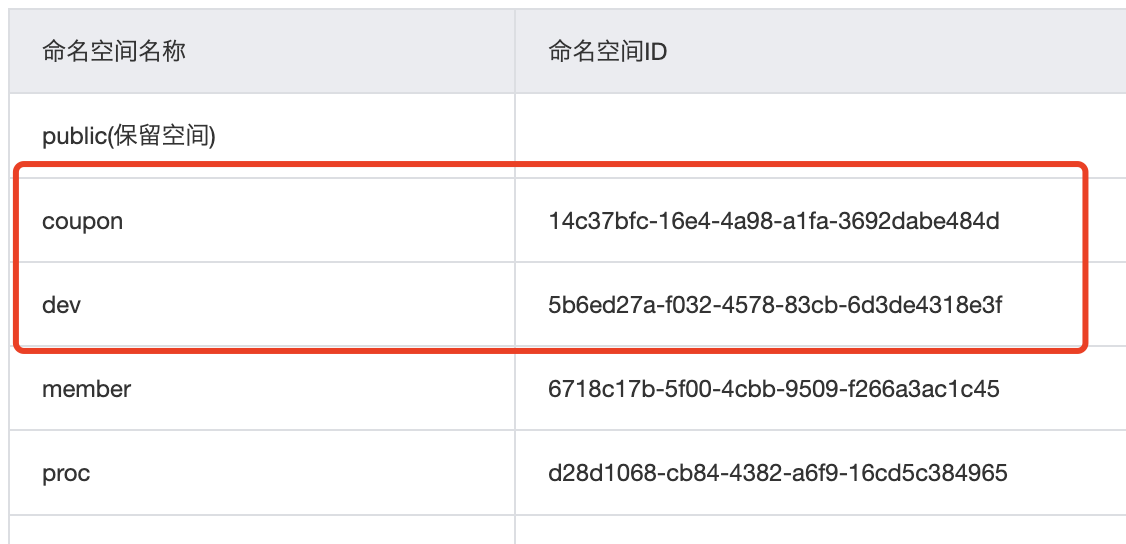
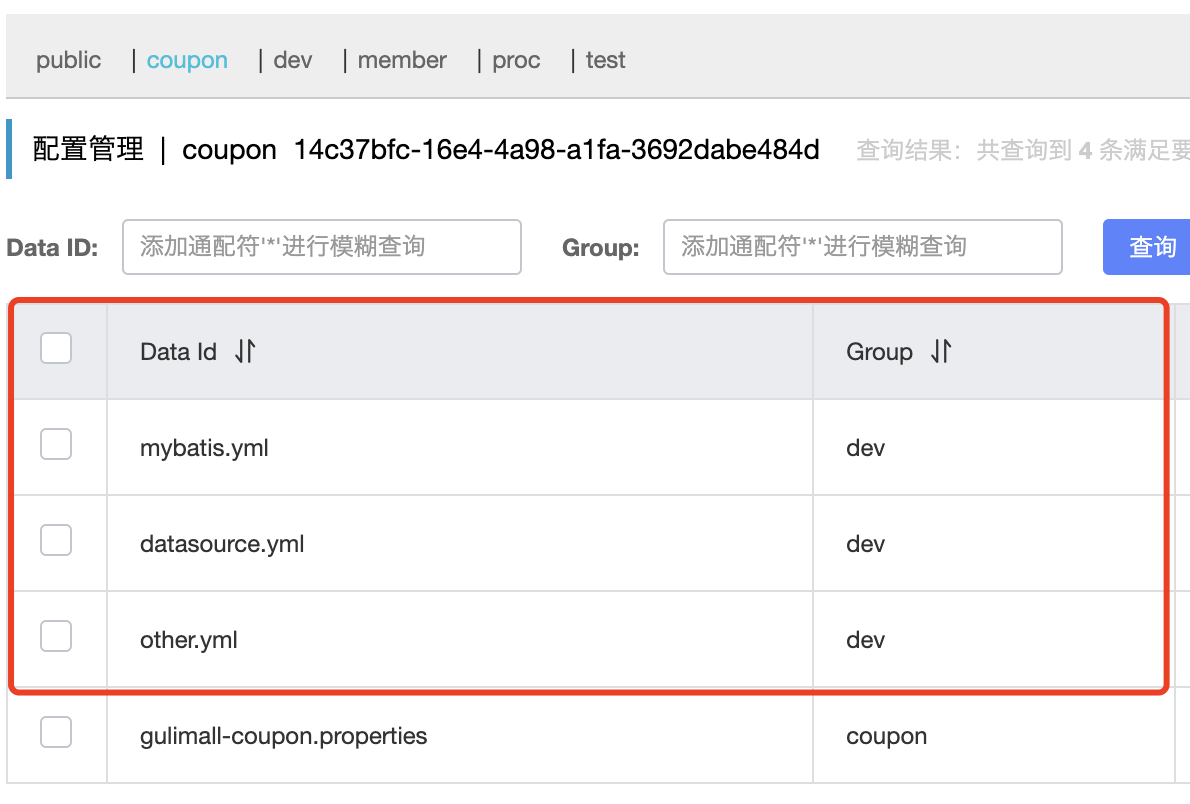
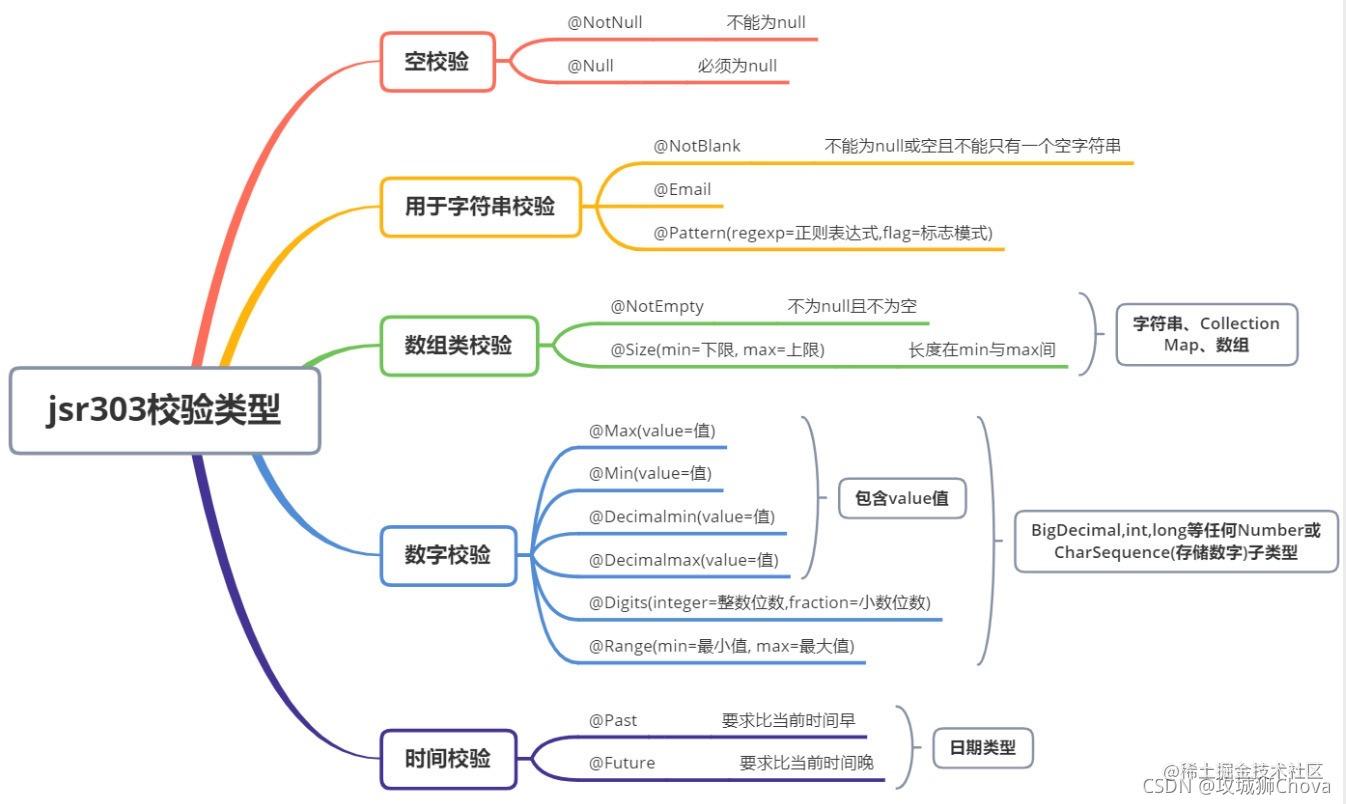
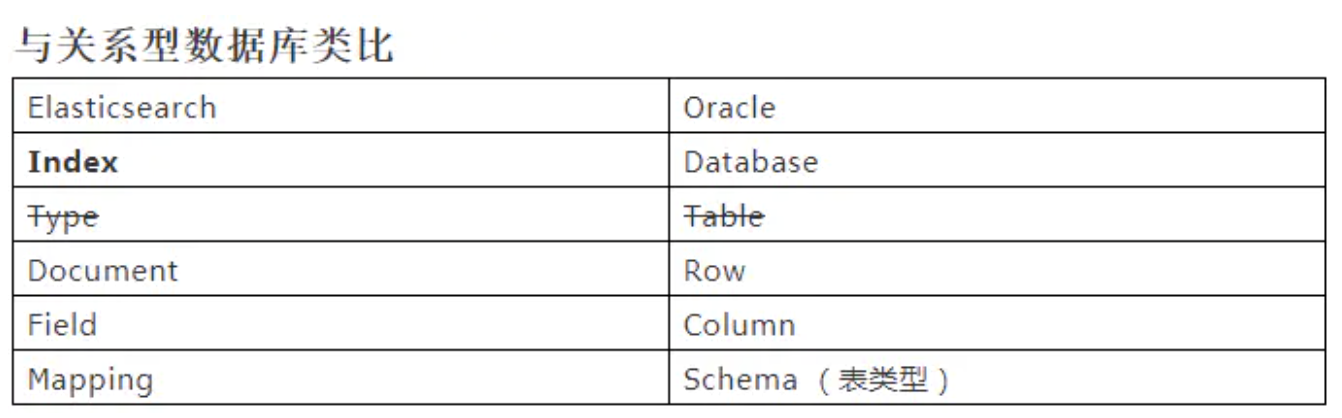
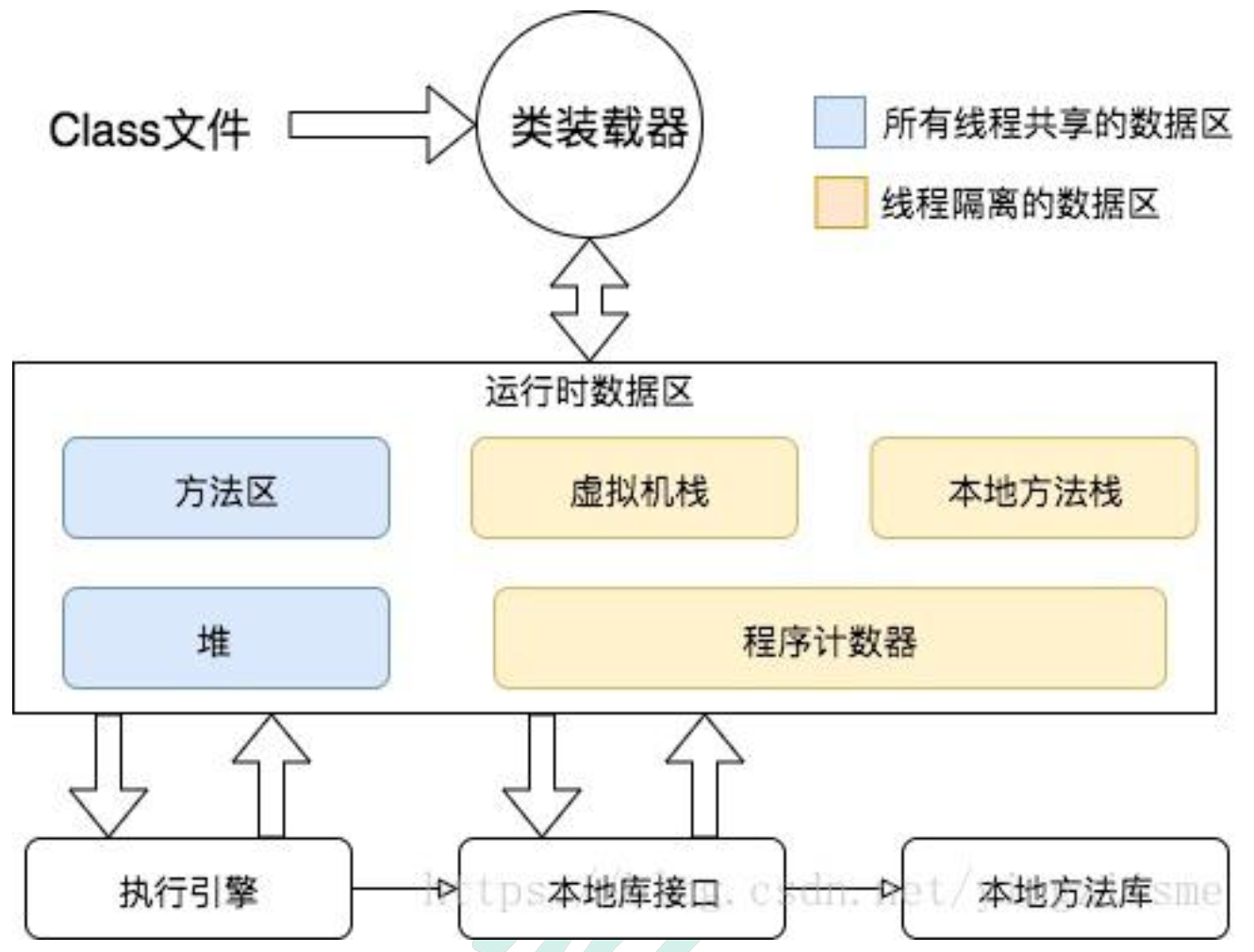
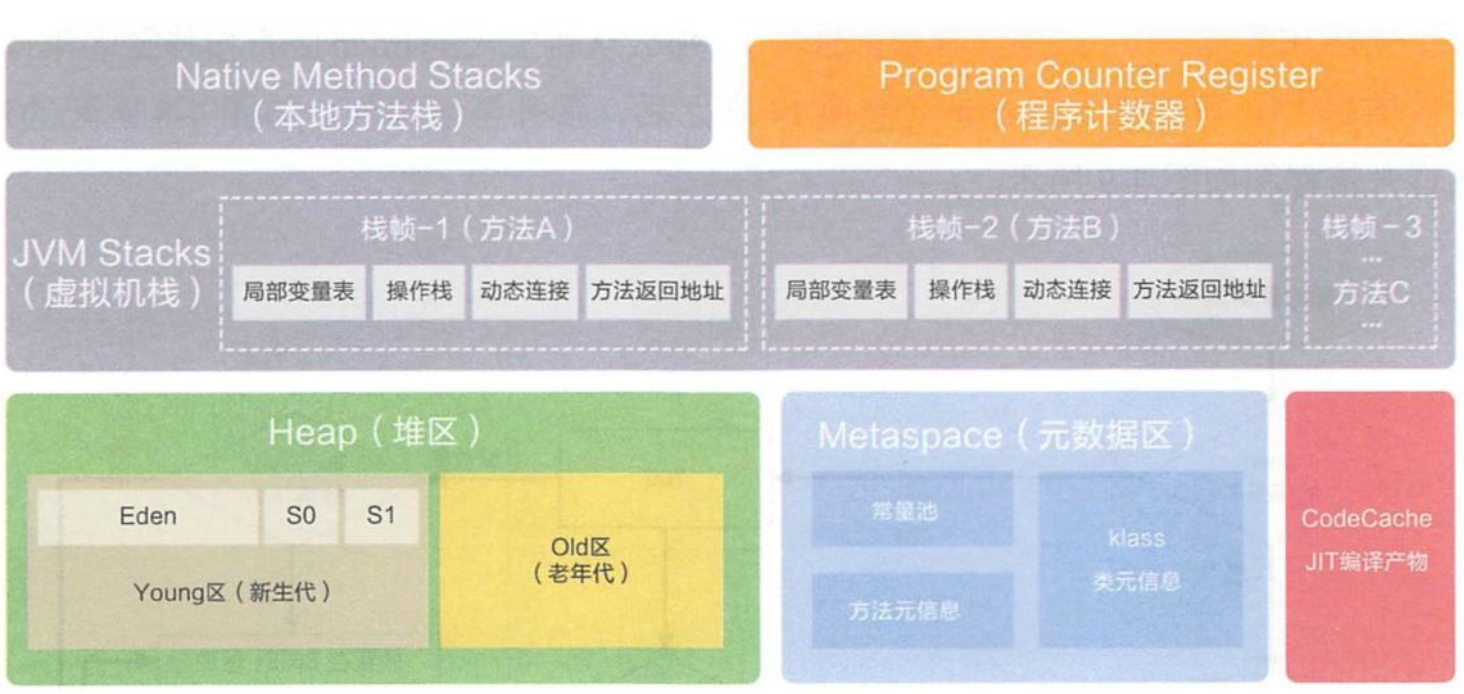
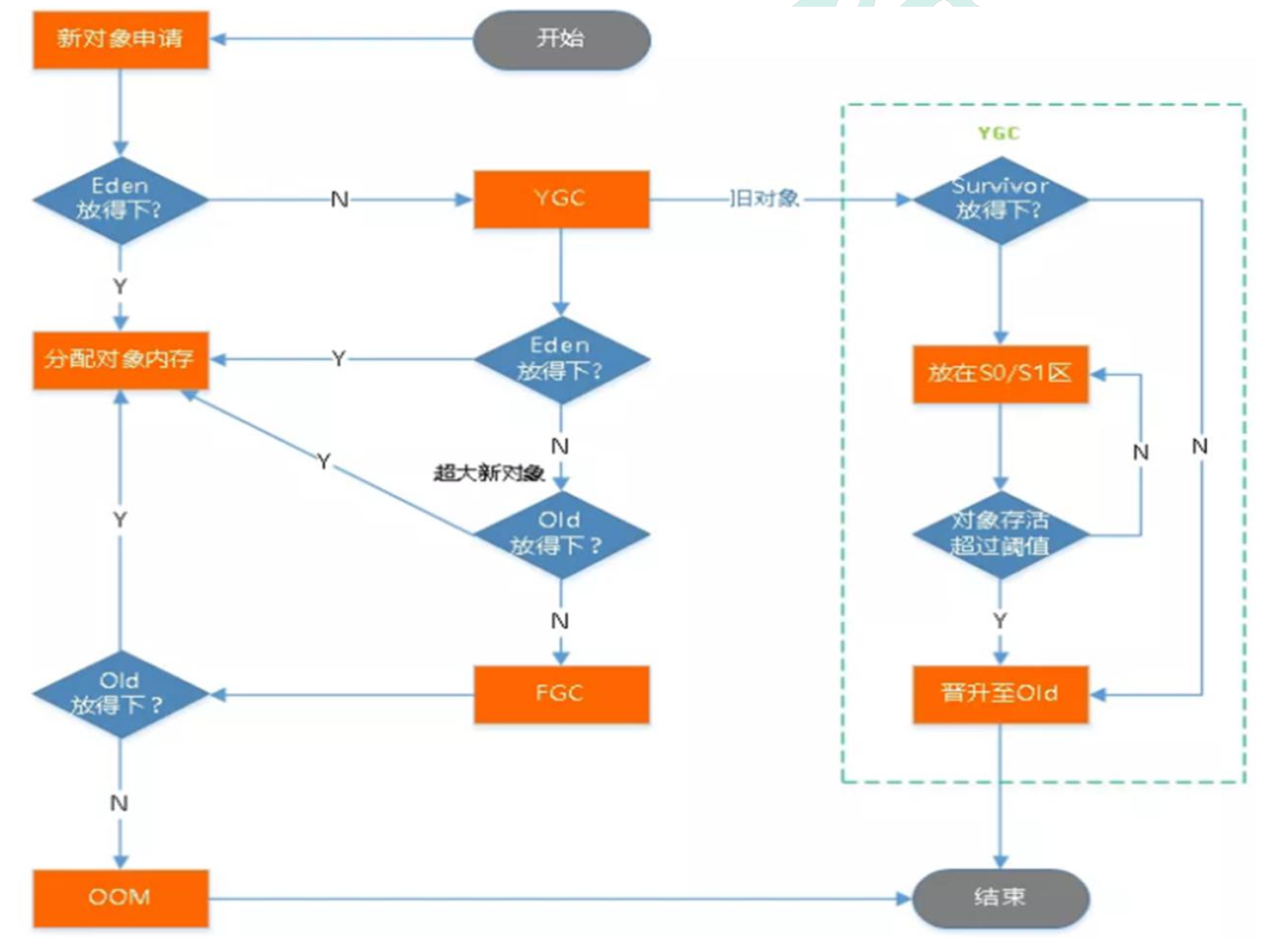
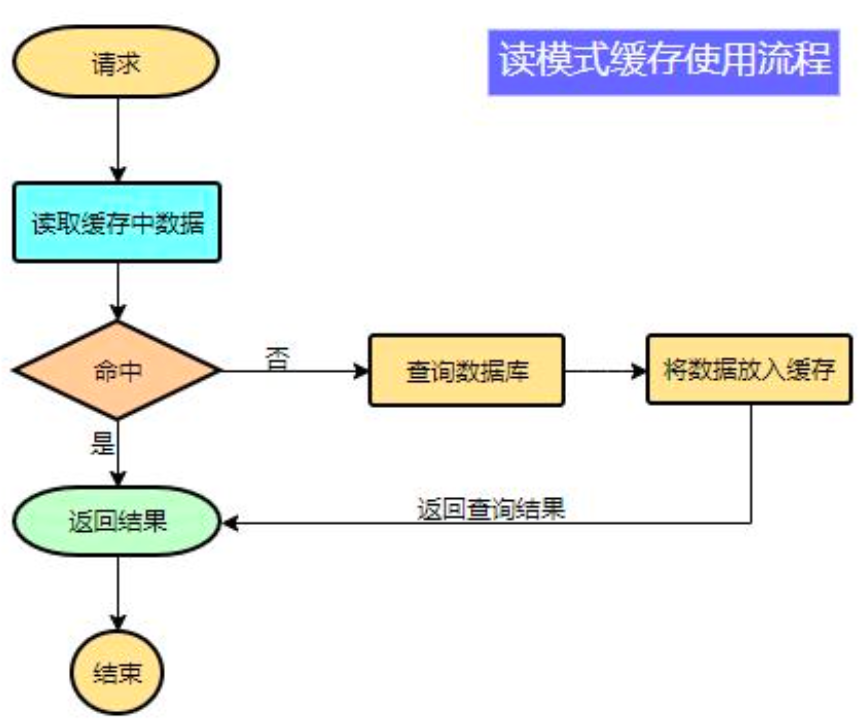
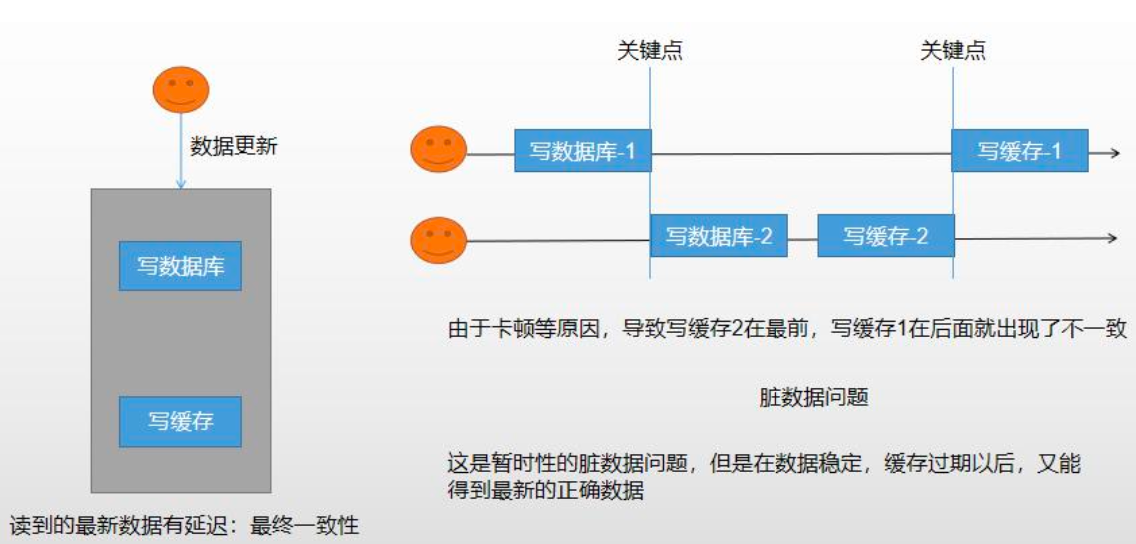
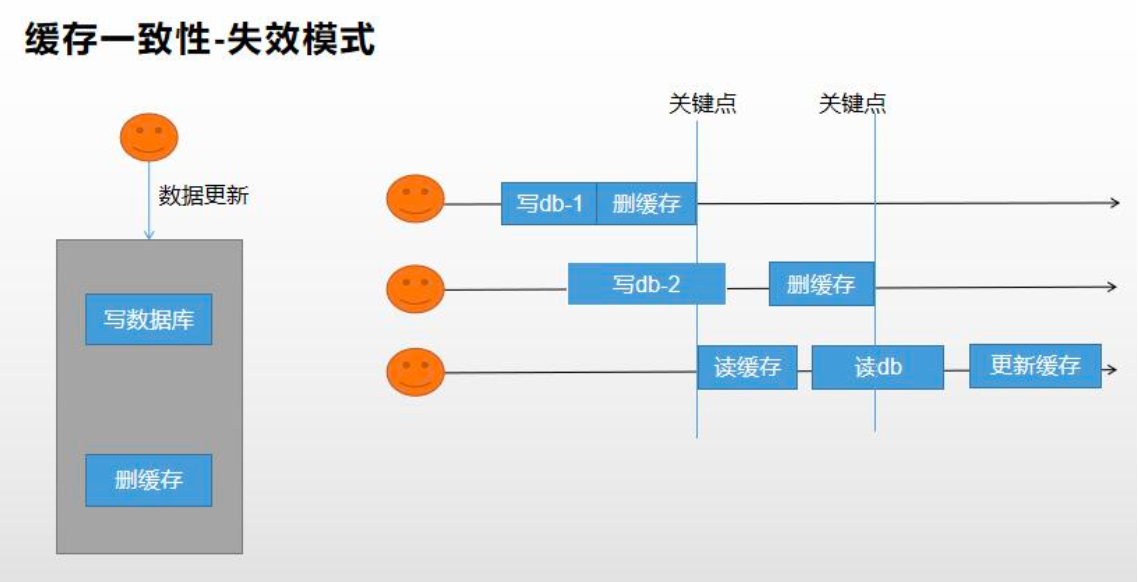
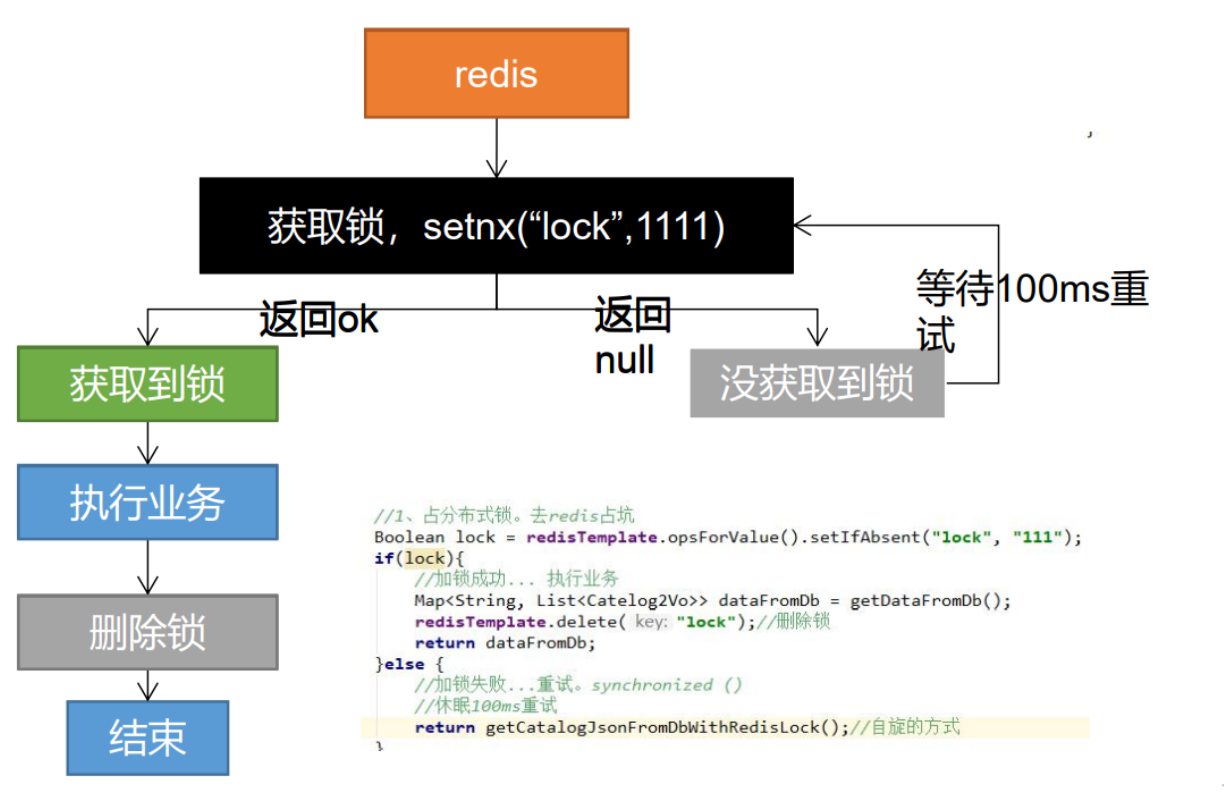

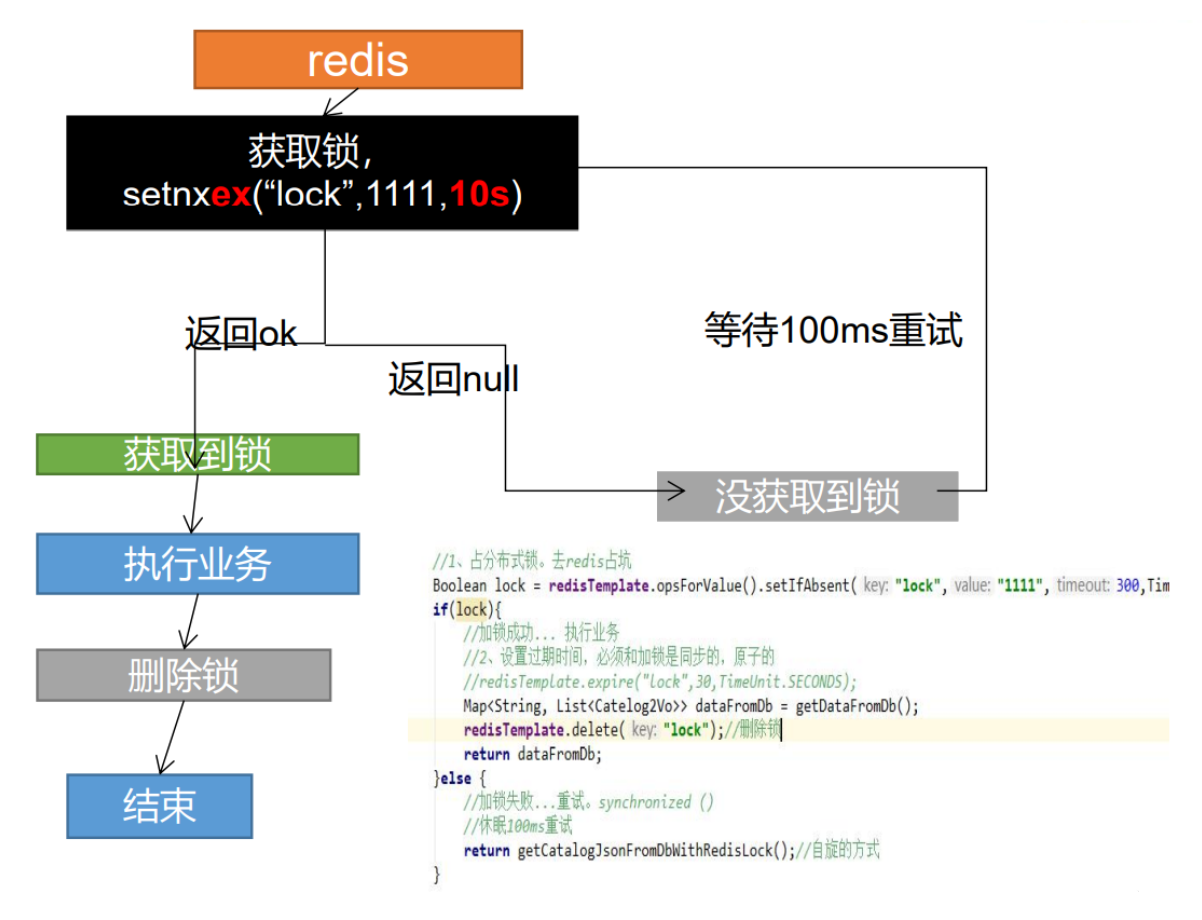
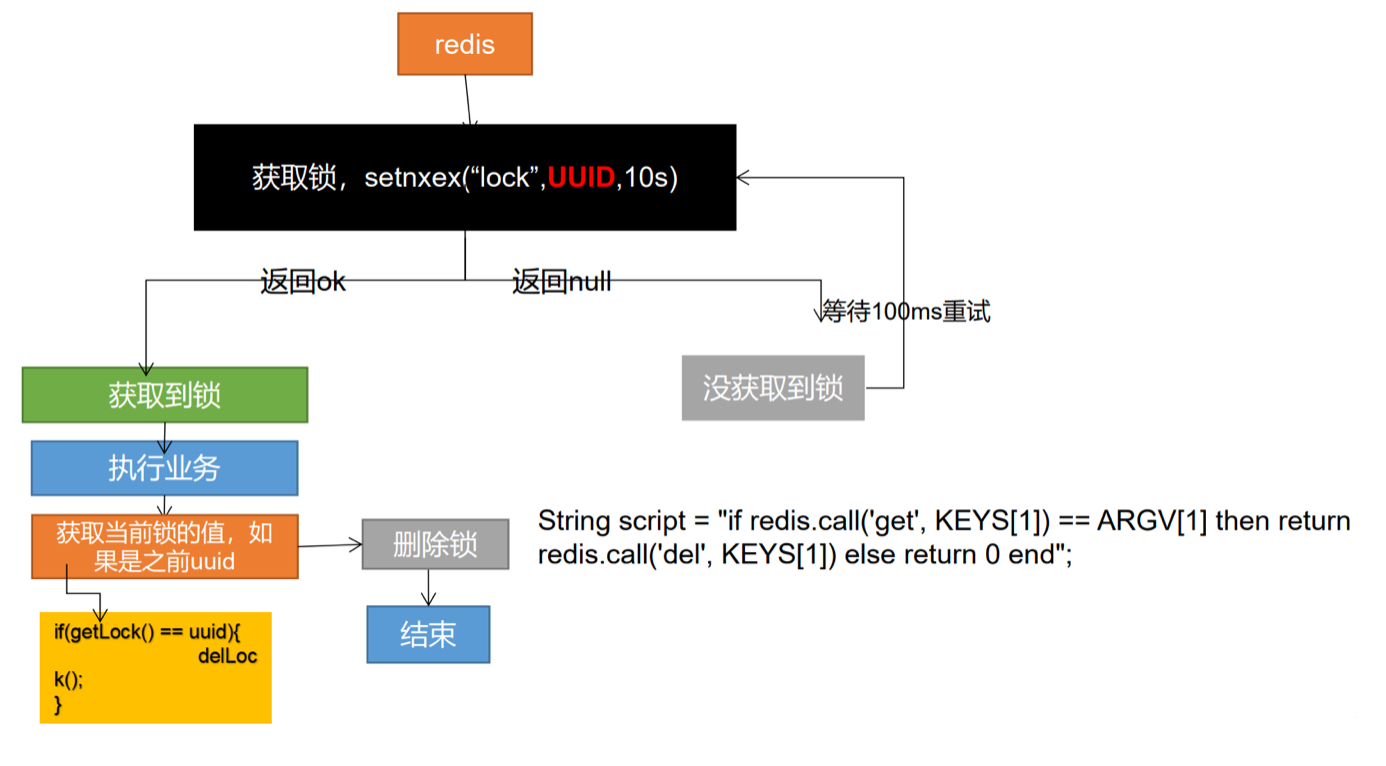
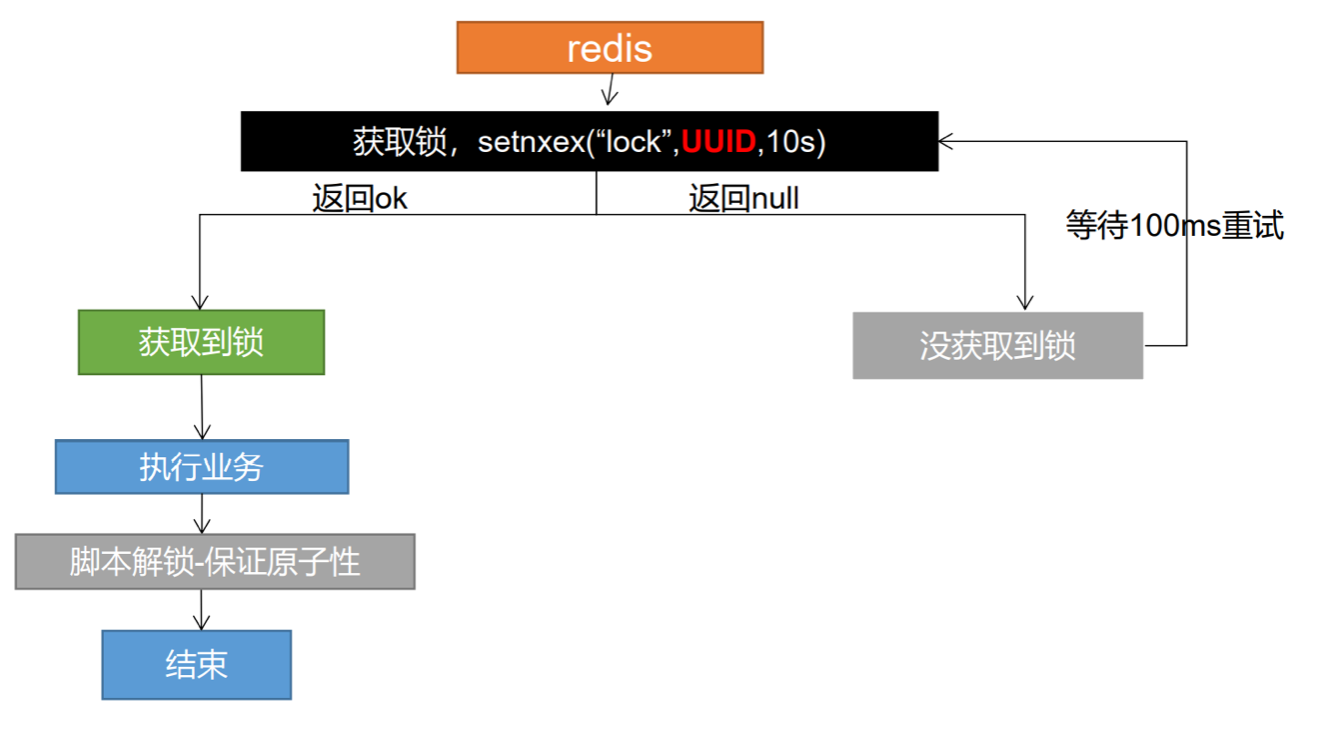
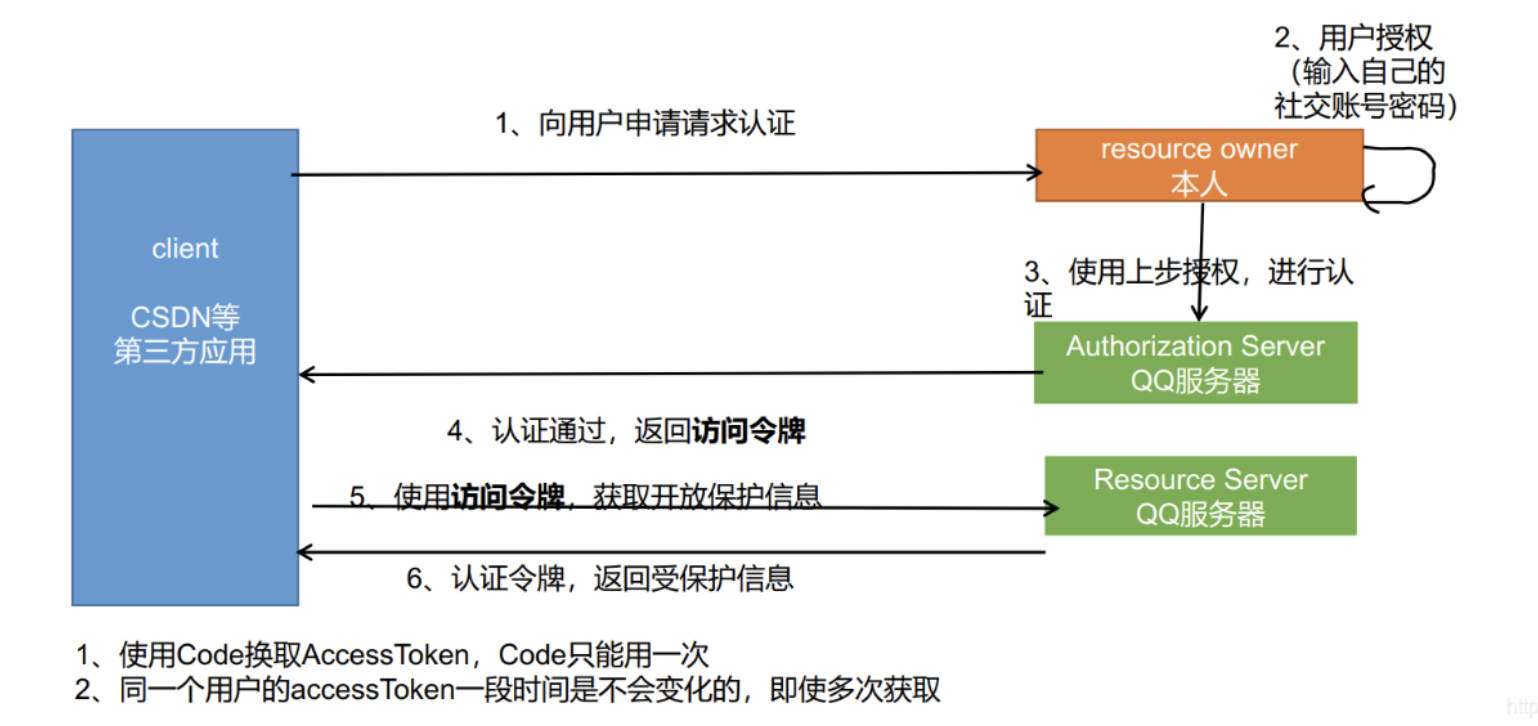
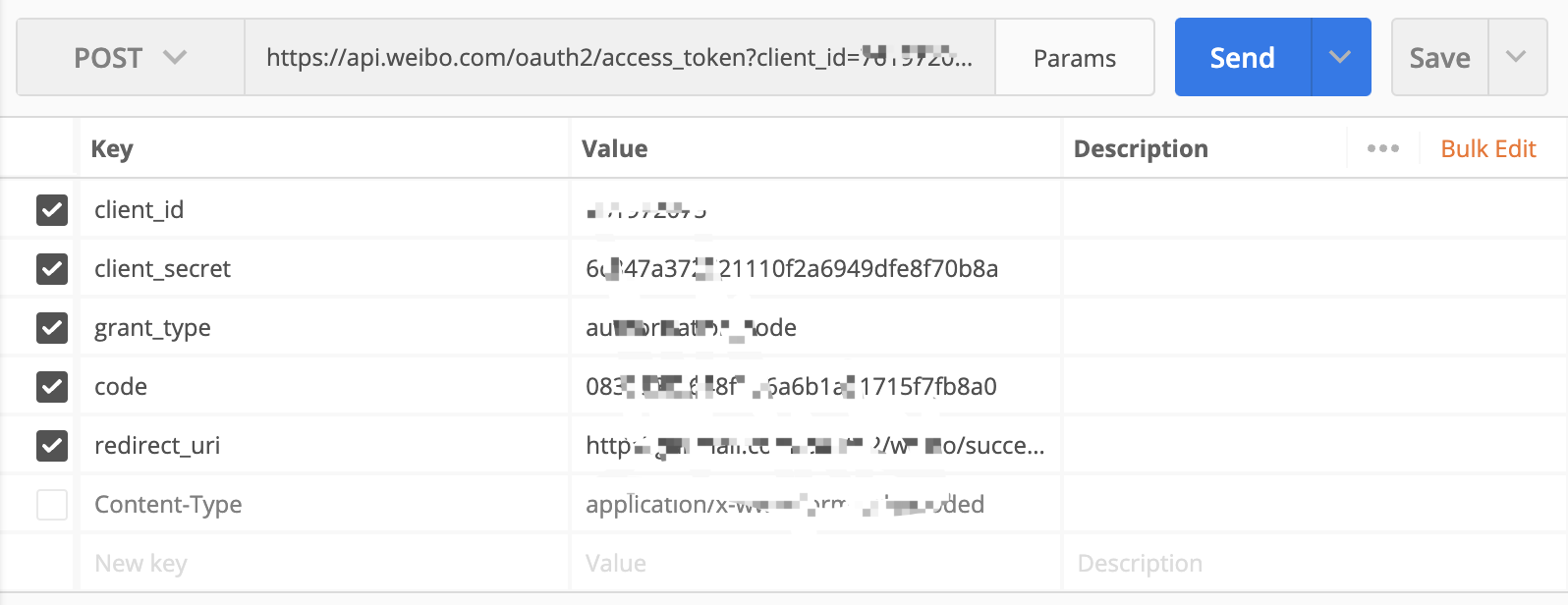
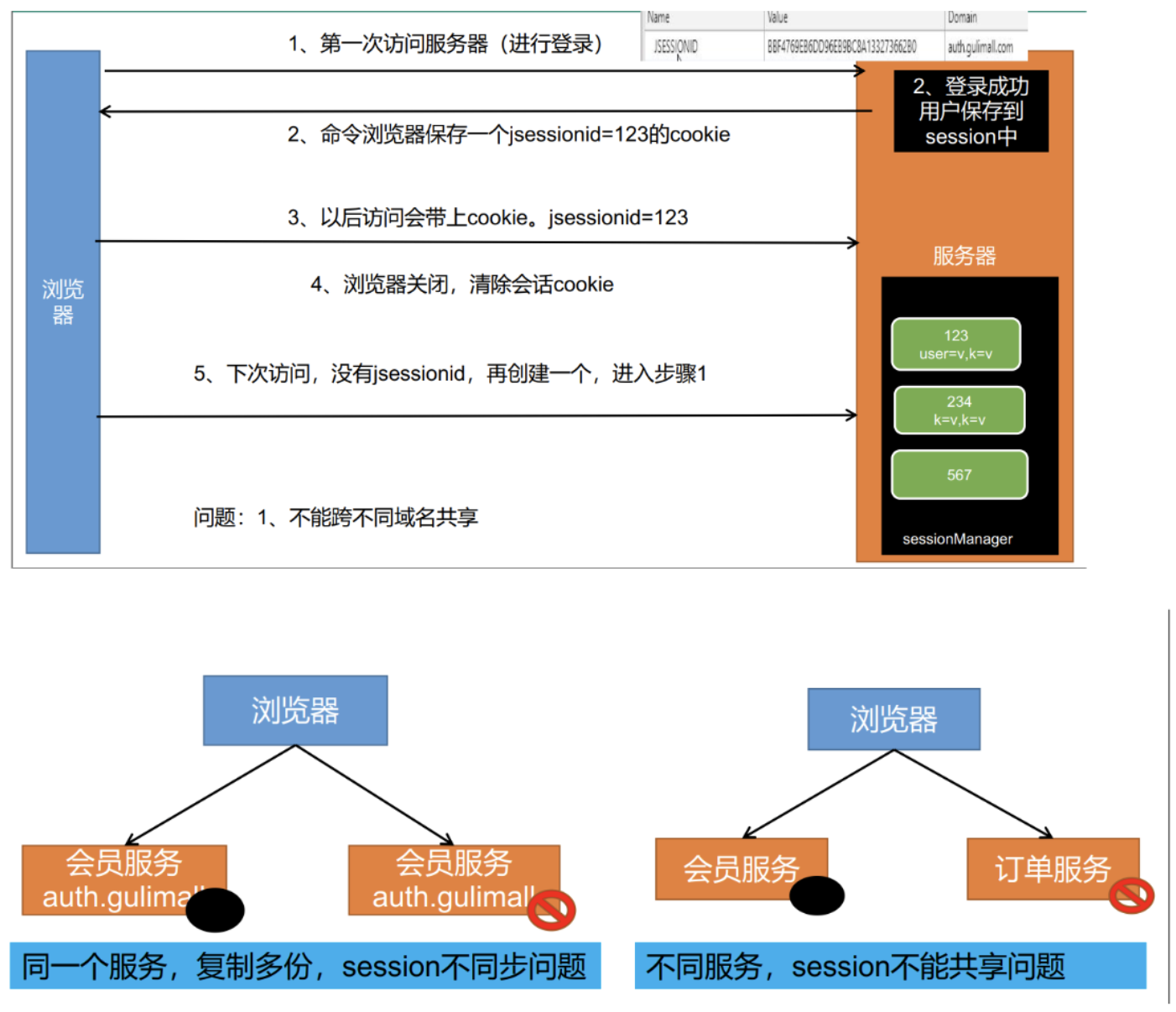
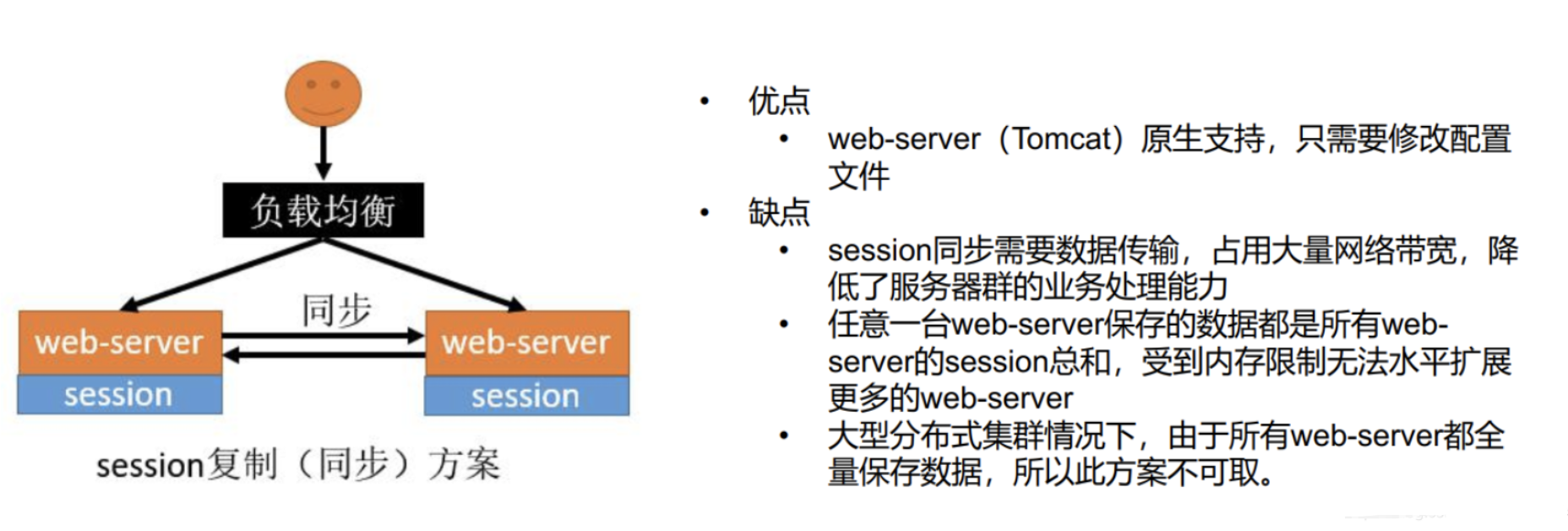

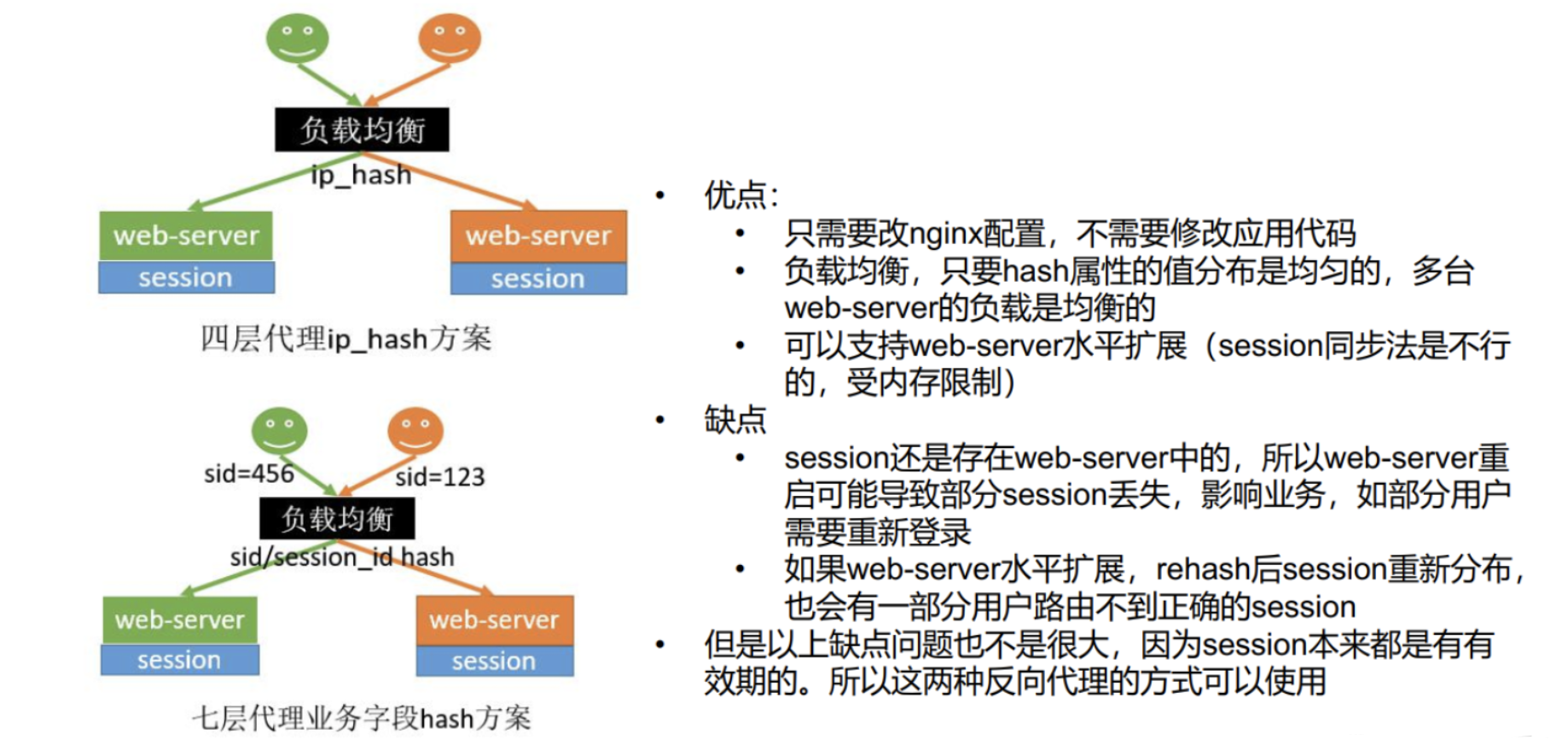
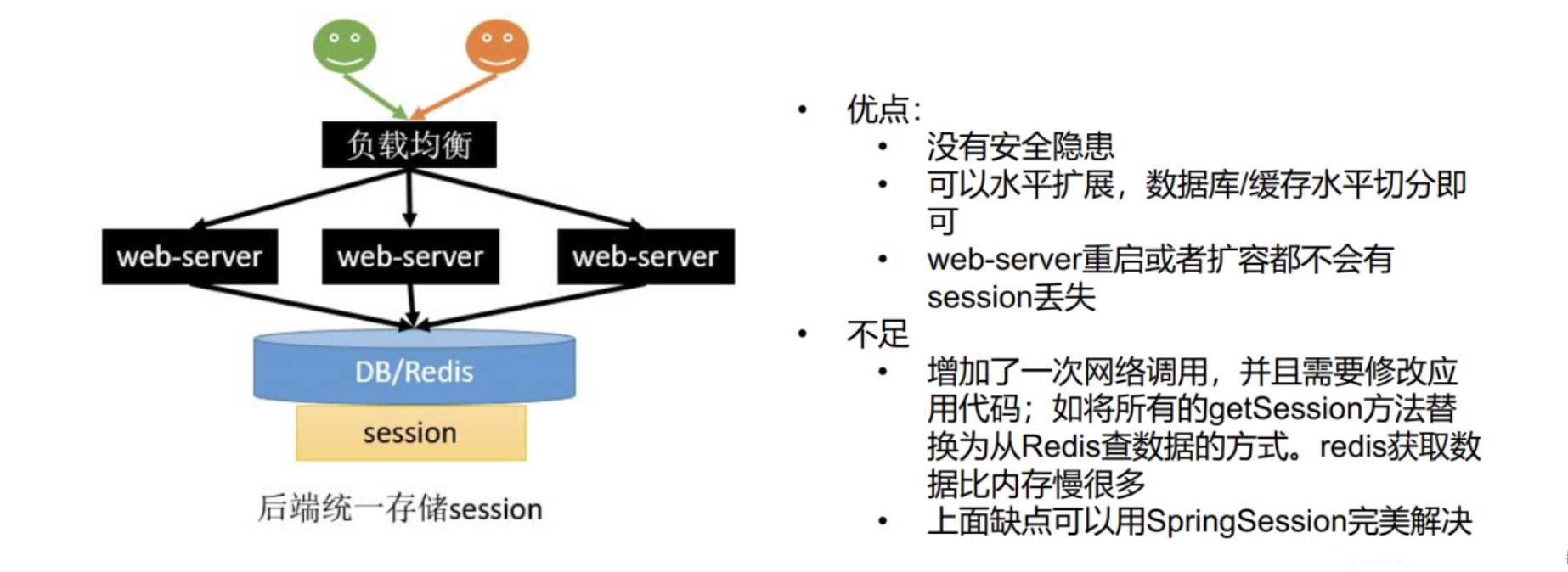
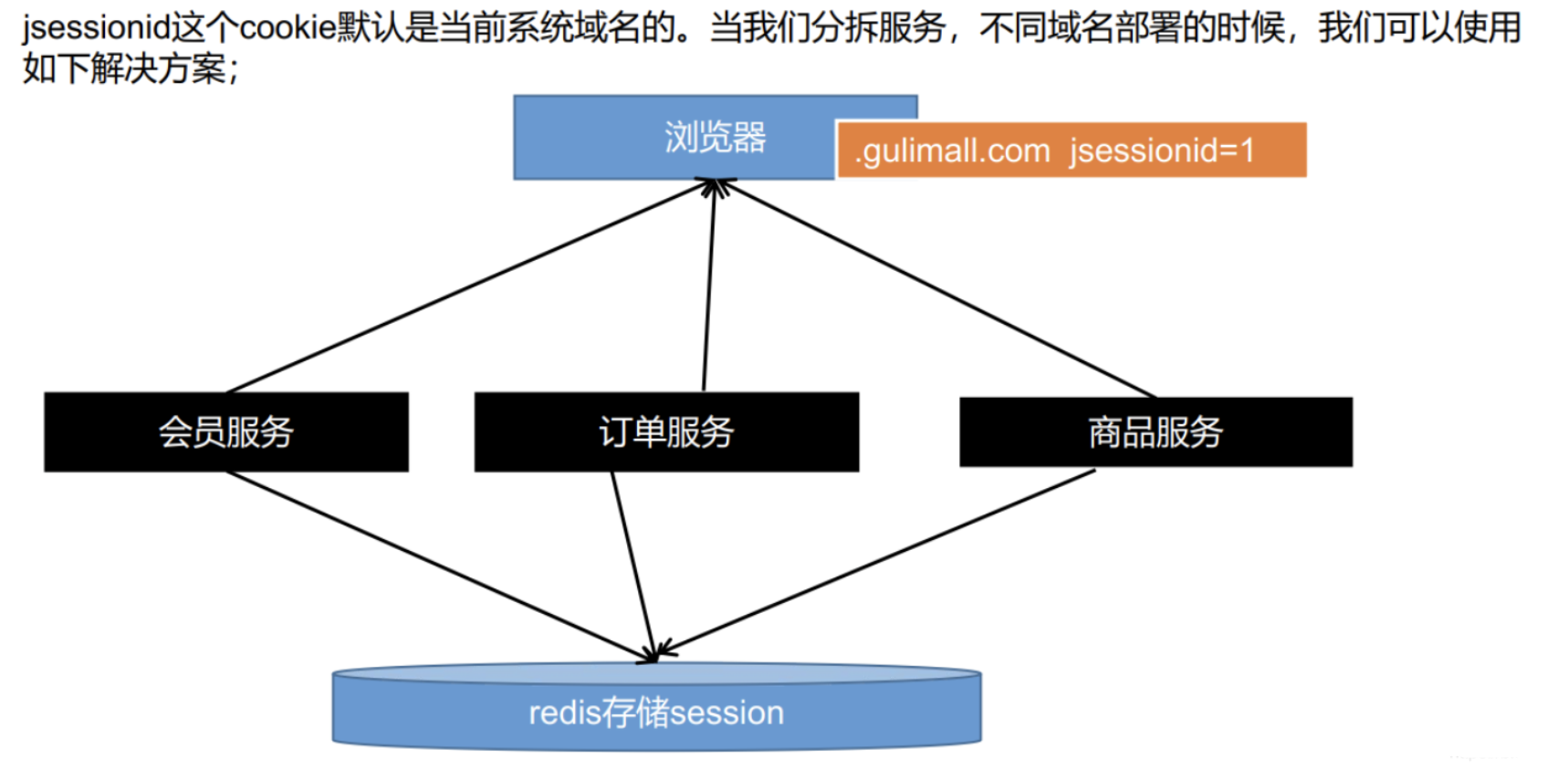
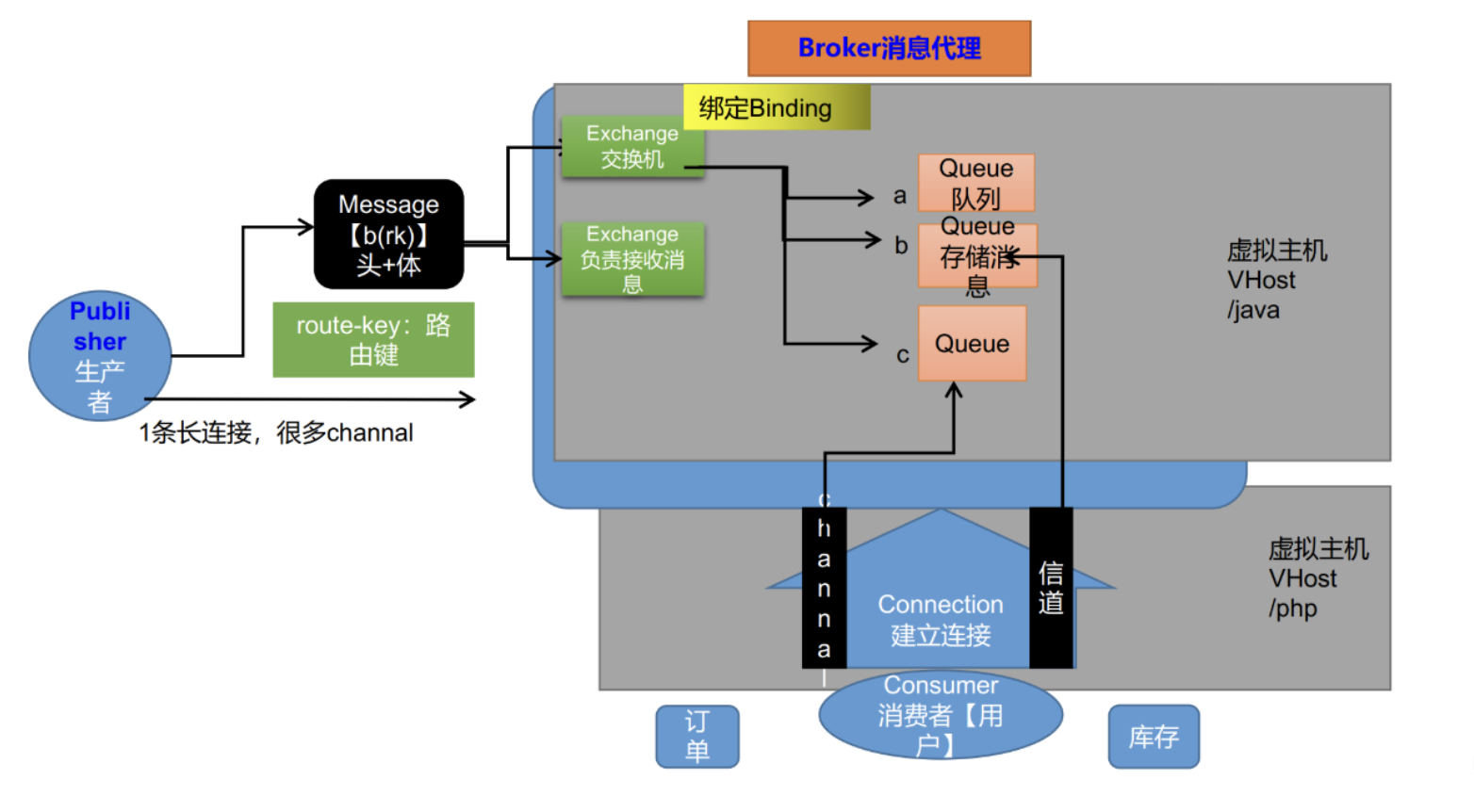
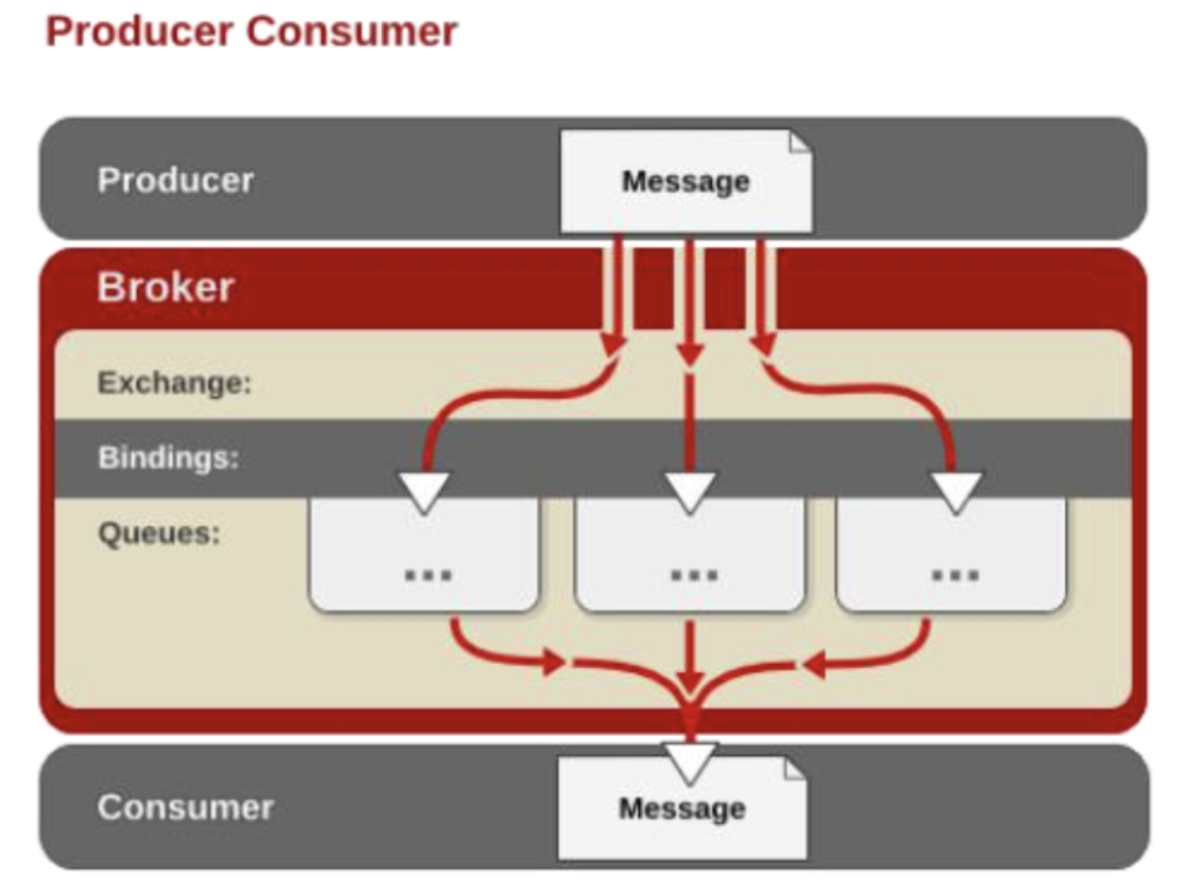
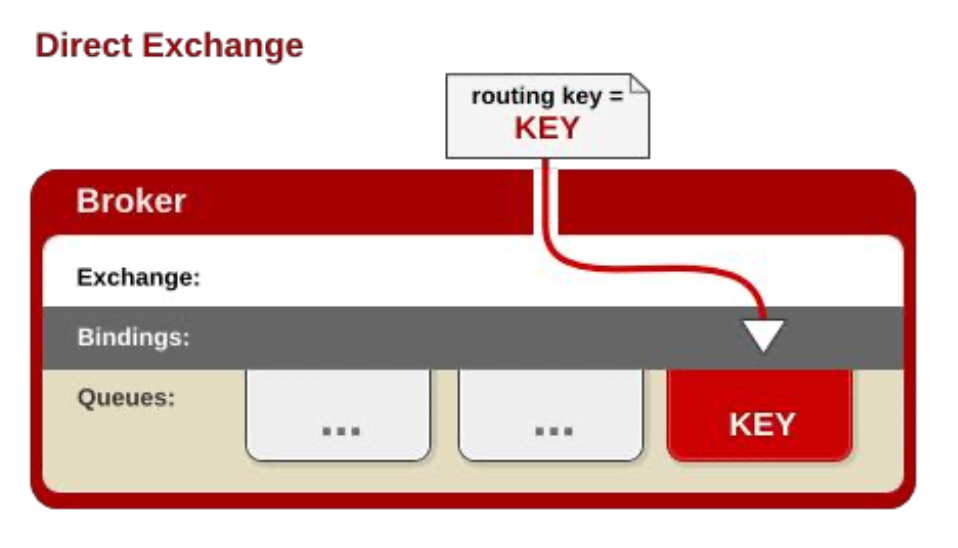
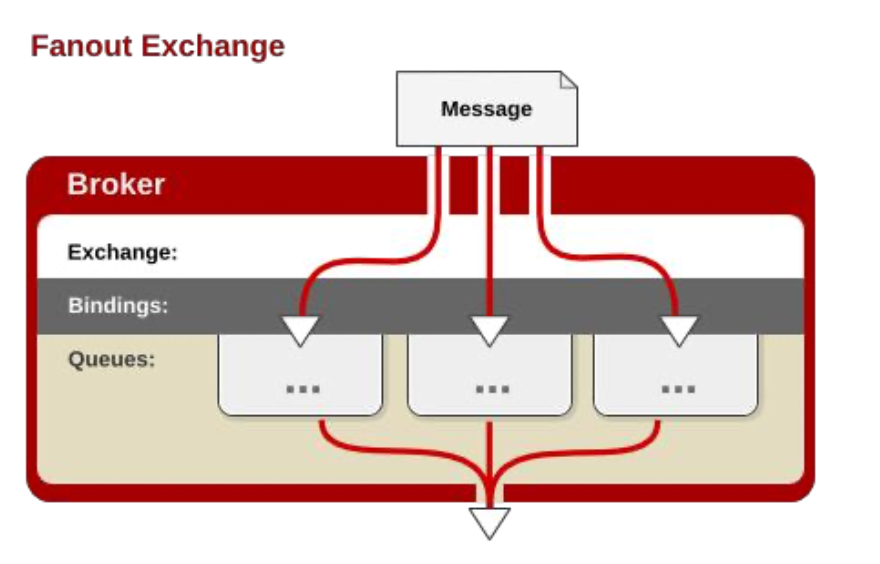
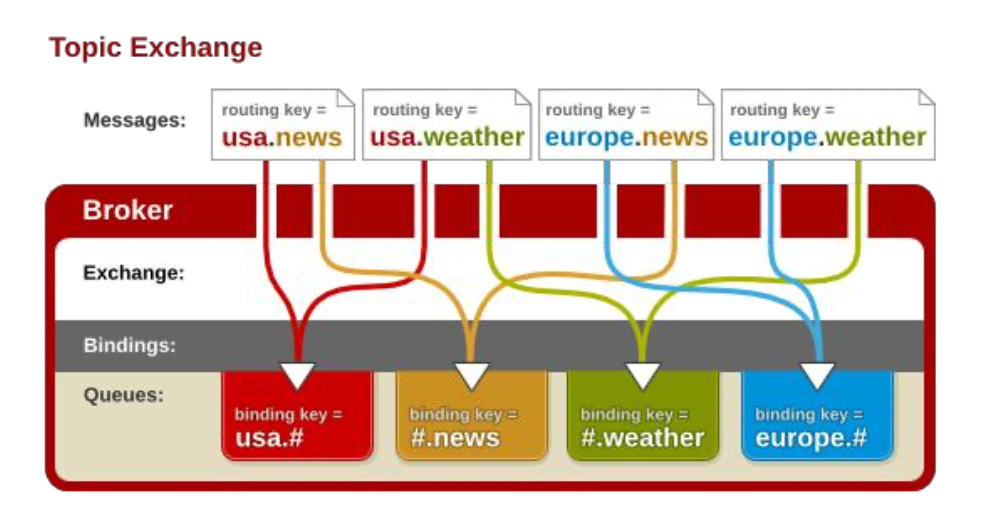
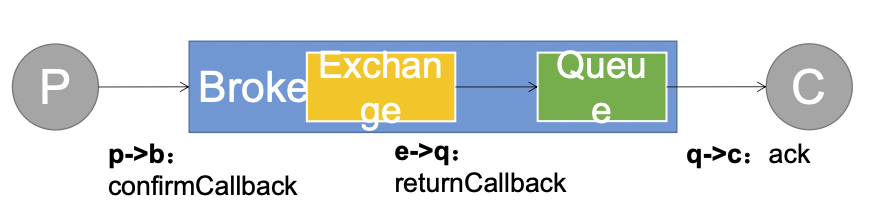
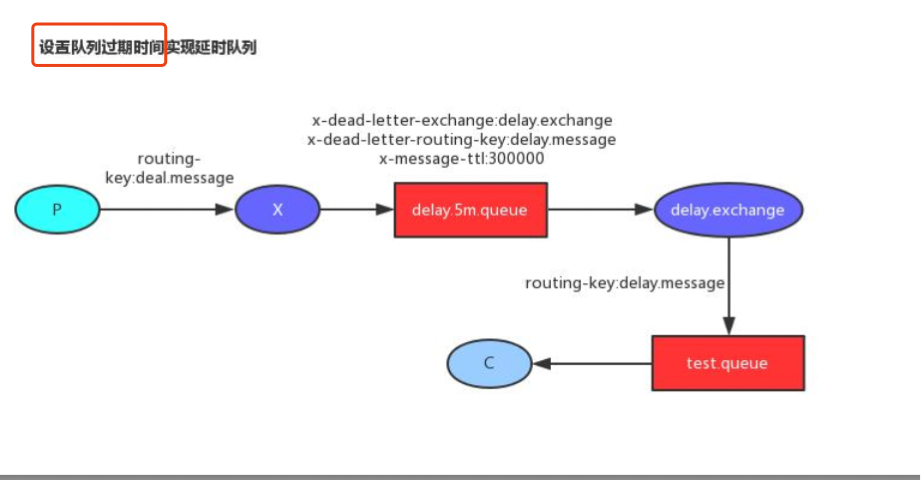
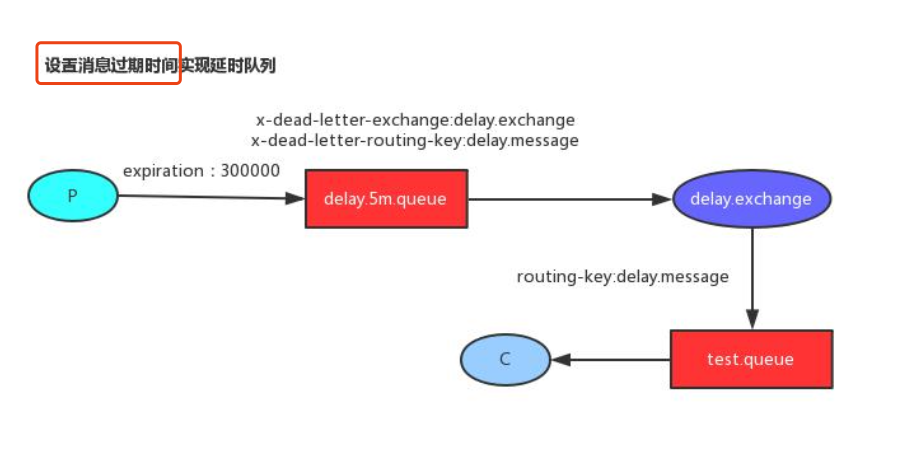
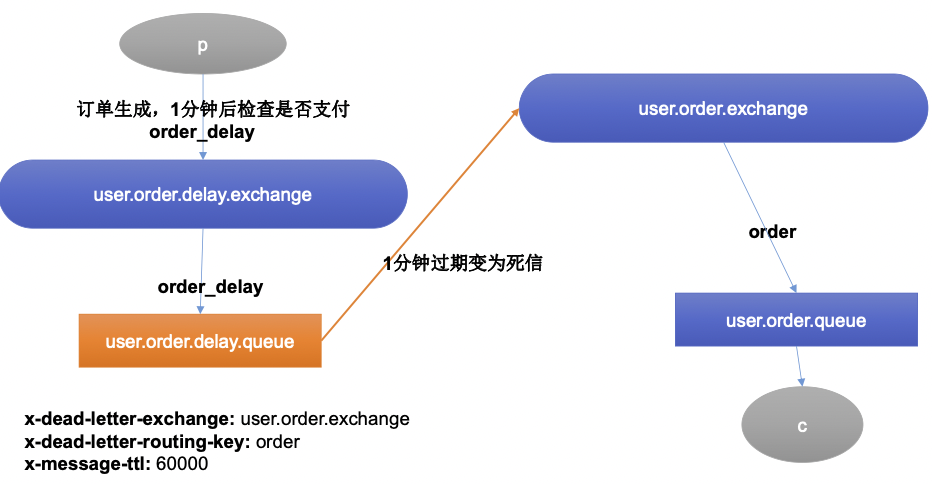
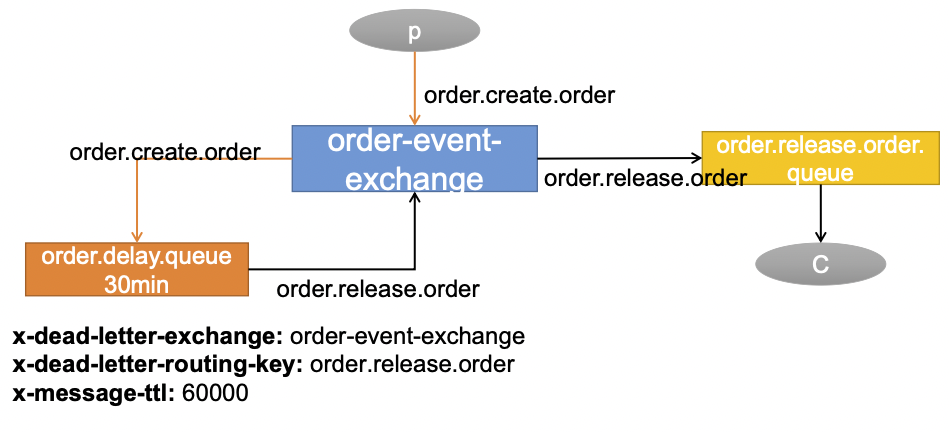
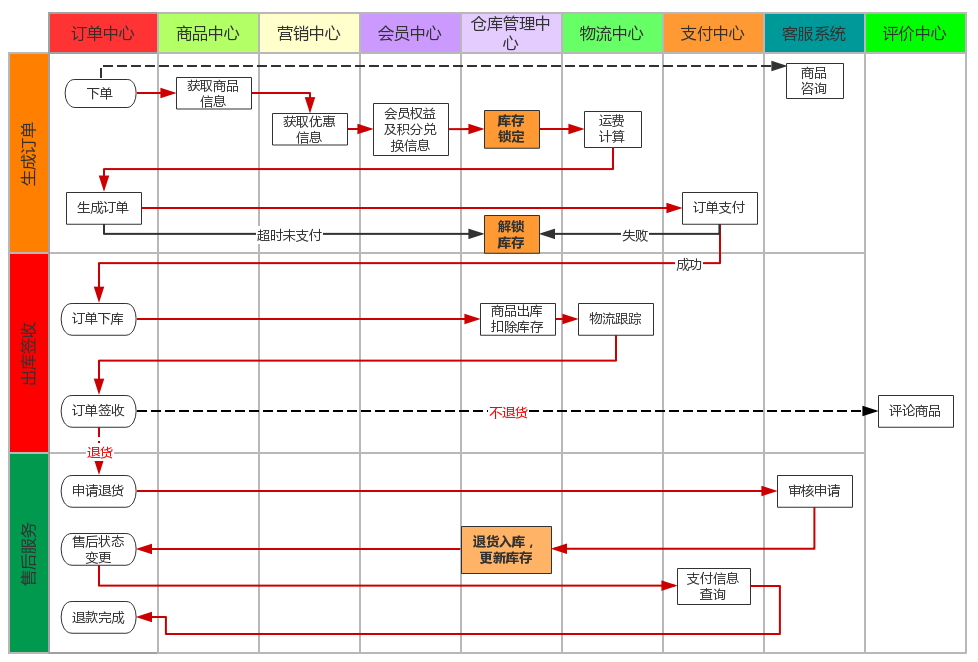
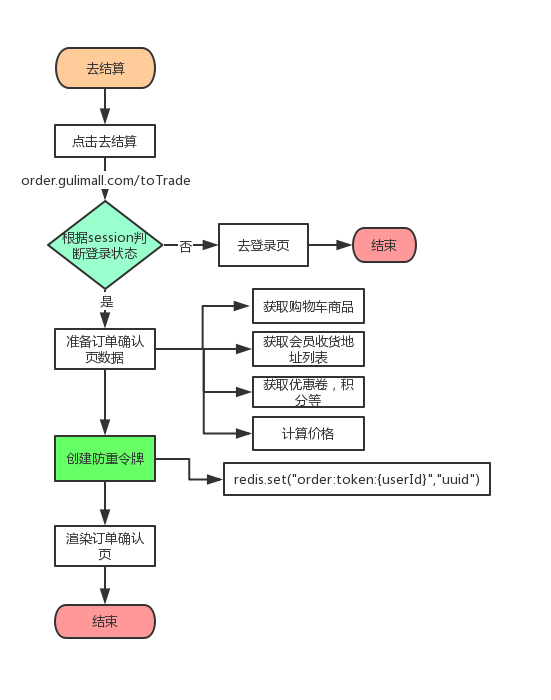
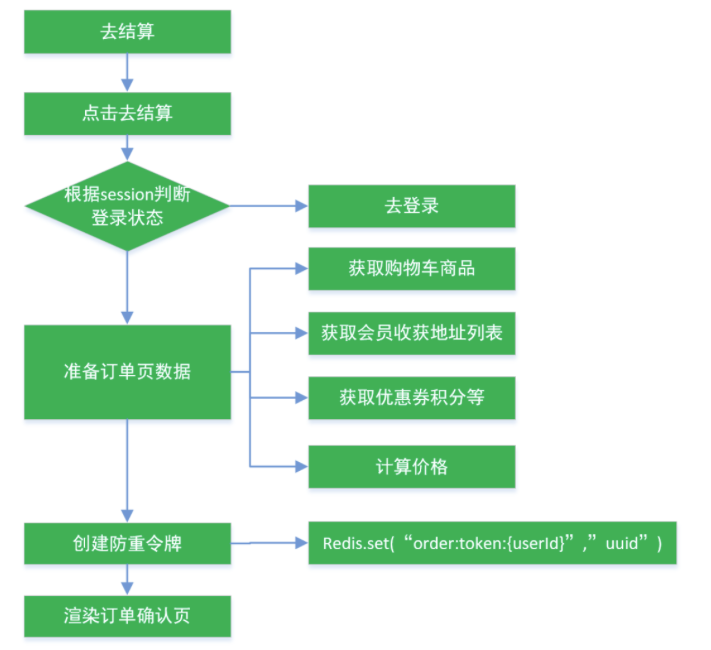
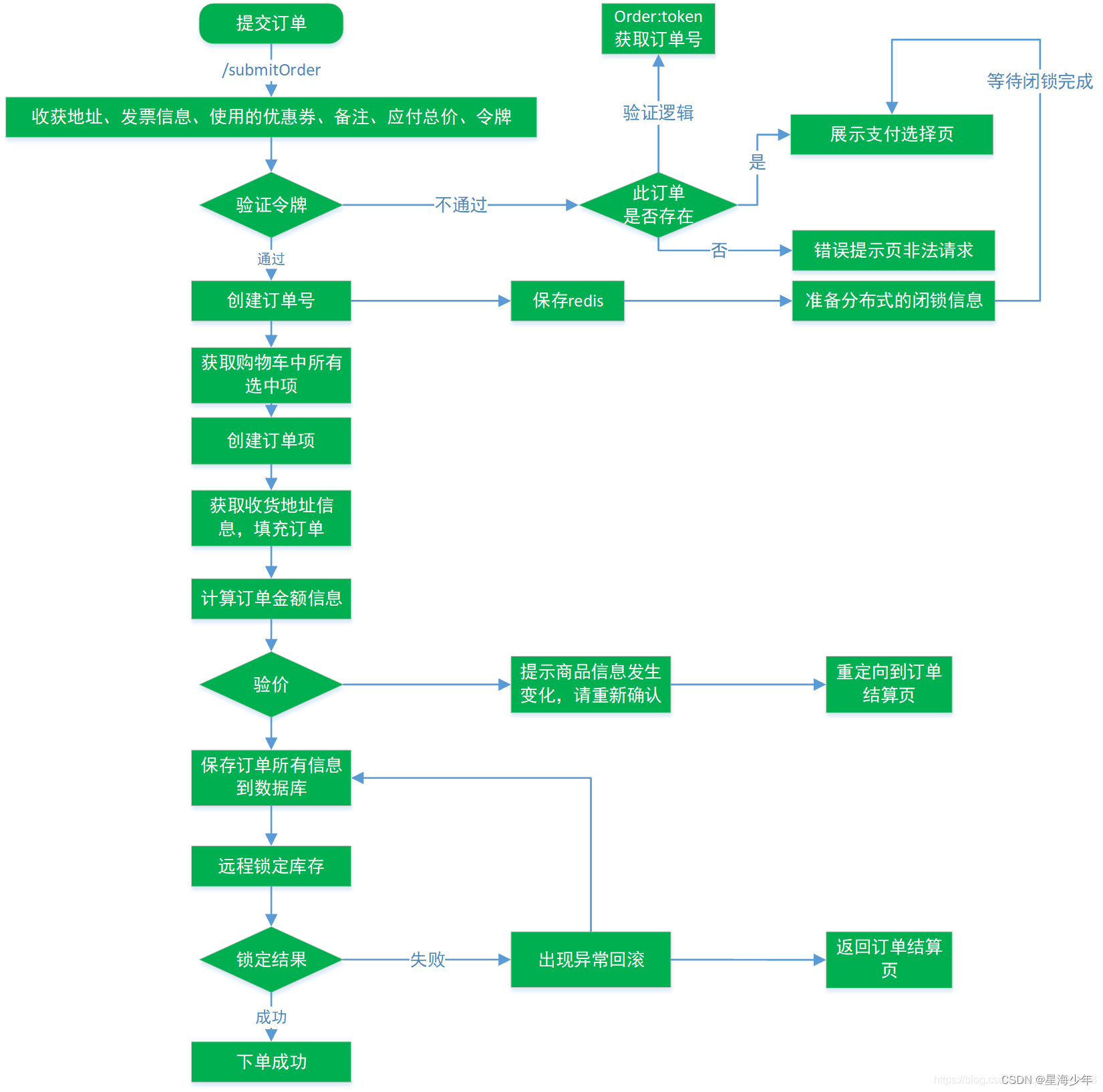
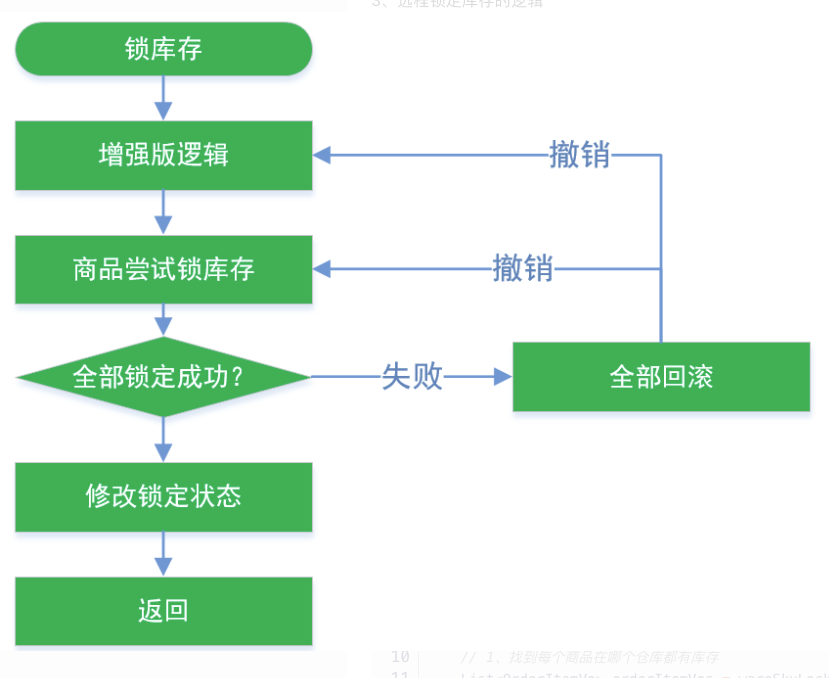
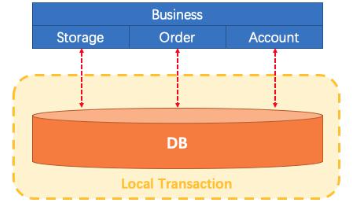
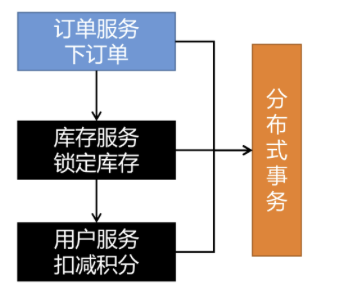
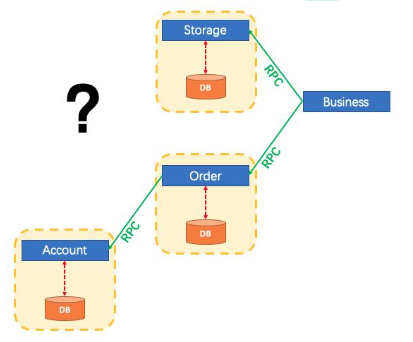
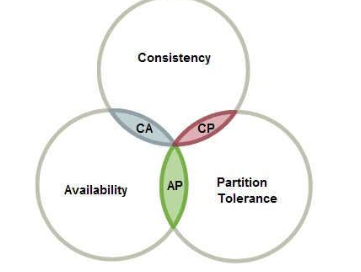
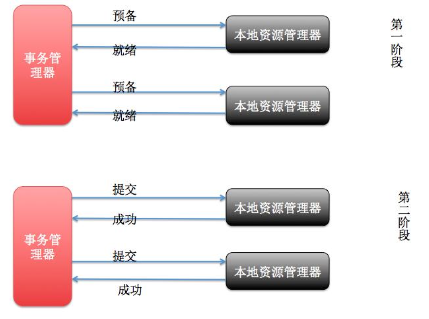
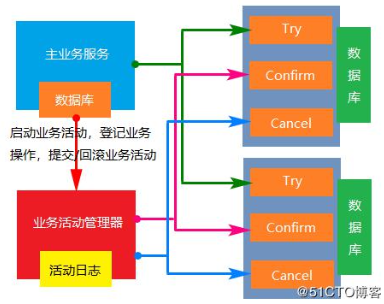
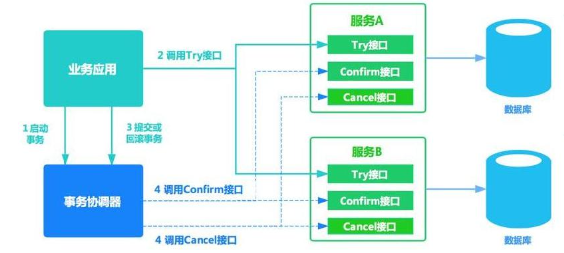
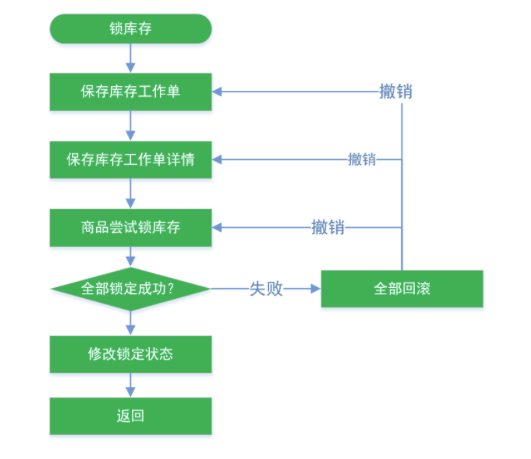
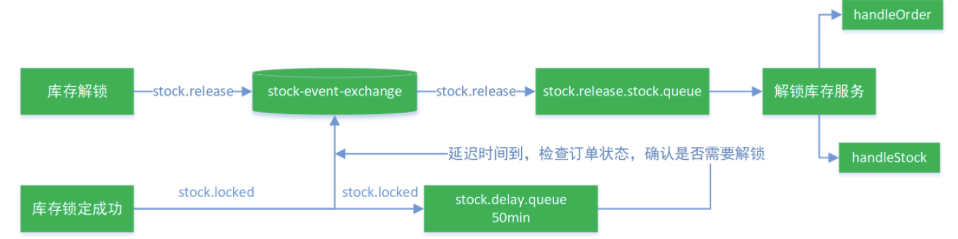
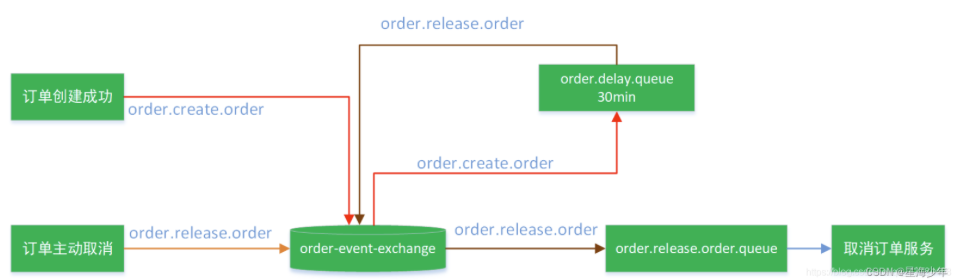
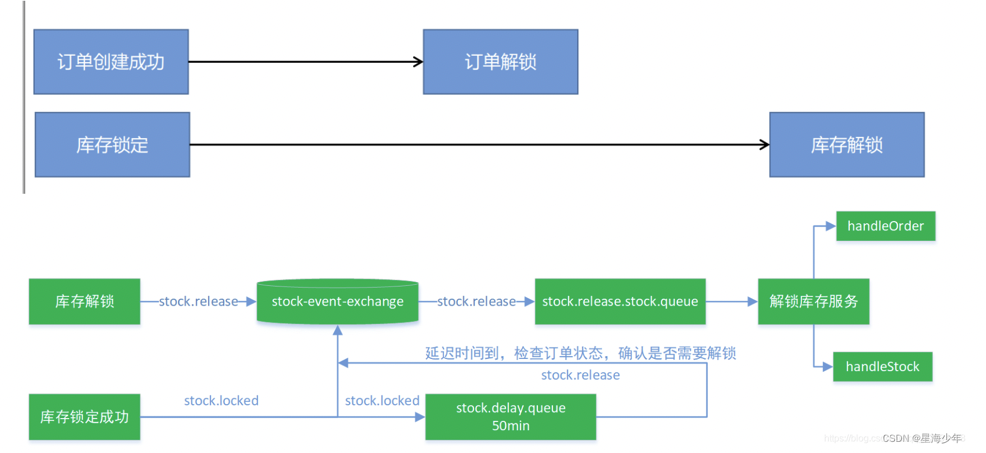
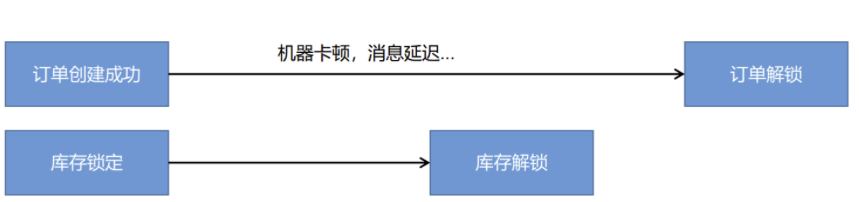
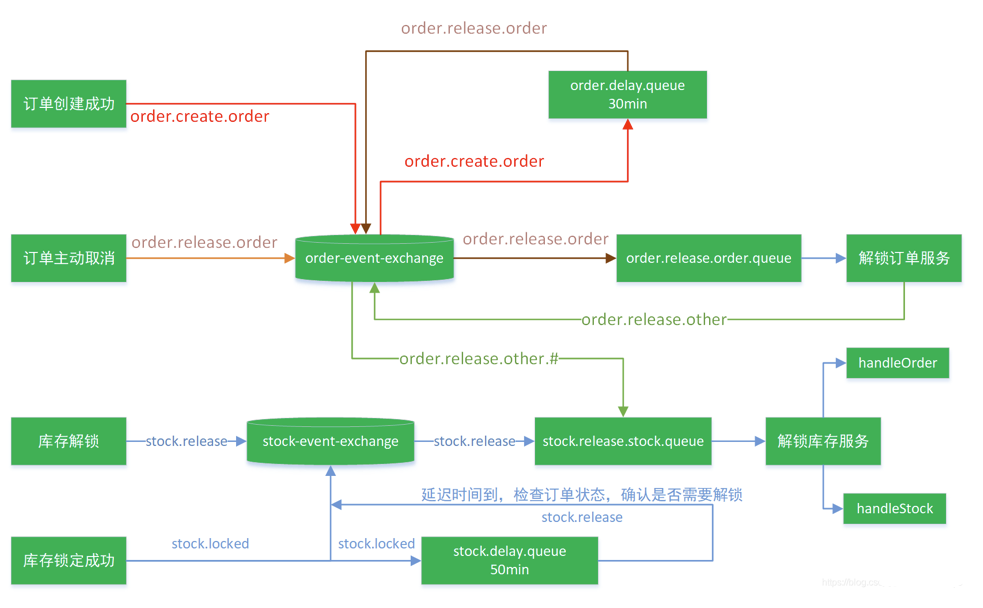
 wechat
wechat alipay
alipay


